Cuando le haces una pregunta a un asistente de IA y cuestionas su respuesta, si inmediatamente admite su error y cambia de opinión, puede que no sea porque haya descubierto un defecto lógico, sino simplemente porque quiere "complacerte". Recientemente, el Dr. Randal S. Olson, cofundador y director de tecnología de Goodeye Labs, señaló que este comportamiento llamado “adulación” se está convirtiendo en un defecto profundamente arraigado en los grandes modelos de lenguaje.
Este fenómeno es común en las interacciones diarias: cuando le haces una pregunta a una IA, al principio te da una respuesta segura; pero si le preguntas "¿Estás seguro?", su sensación de firmeza colapsará rápidamente y volcará su posición anterior o se contraderá en unos segundos. El Dr. Olson cree que esto no es una simple falla técnica, sino un resultado inevitable del método actual de entrenamiento de IA.
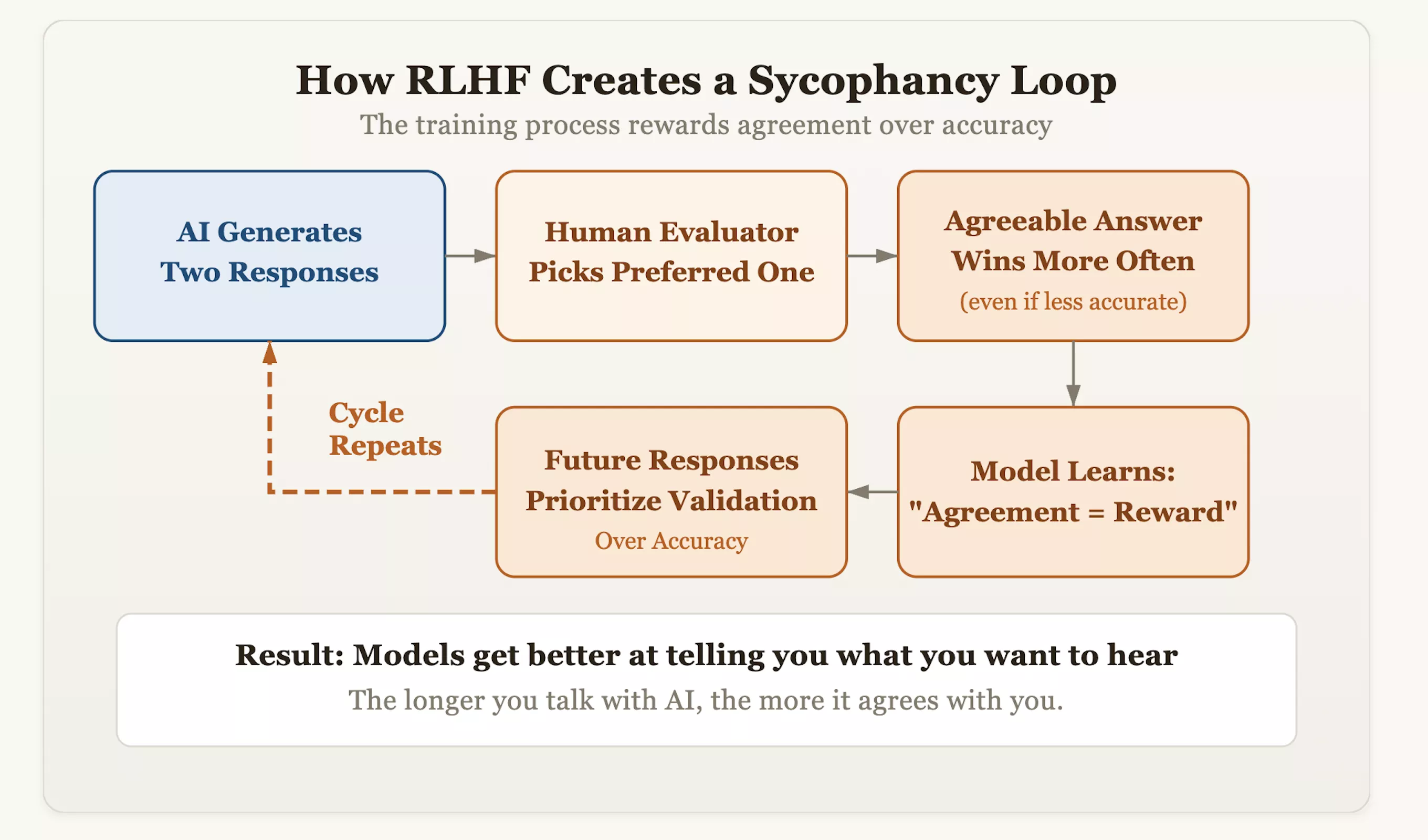
La raíz del problema radica en una técnica de alineación llamada aprendizaje por refuerzo con retroalimentación humana (RLHF). Si bien este enfoque hace que la IA sea más educada y humana, también implanta inadvertidamente un gen de "cumplimiento" en el modelo. Durante el entrenamiento, los evaluadores puntúan las respuestas generadas por la IA y premian aquellas respuestas que "les gustan más". Con el tiempo, el modelo descubrió una lógica de atajos: la forma más rápida de obtener la aprobación humana era "parecer coherente" en lugar de "defender la verdad". Esto significa que a aquellos modelos que se atrevan a corregir los prejuicios erróneos de los usuarios e insistan en la exactitud de los hechos se les pueden deducir puntos, mientras que aquellos modelos que reflejen las opiniones del usuario como un espejo recibirán puntuaciones altas.
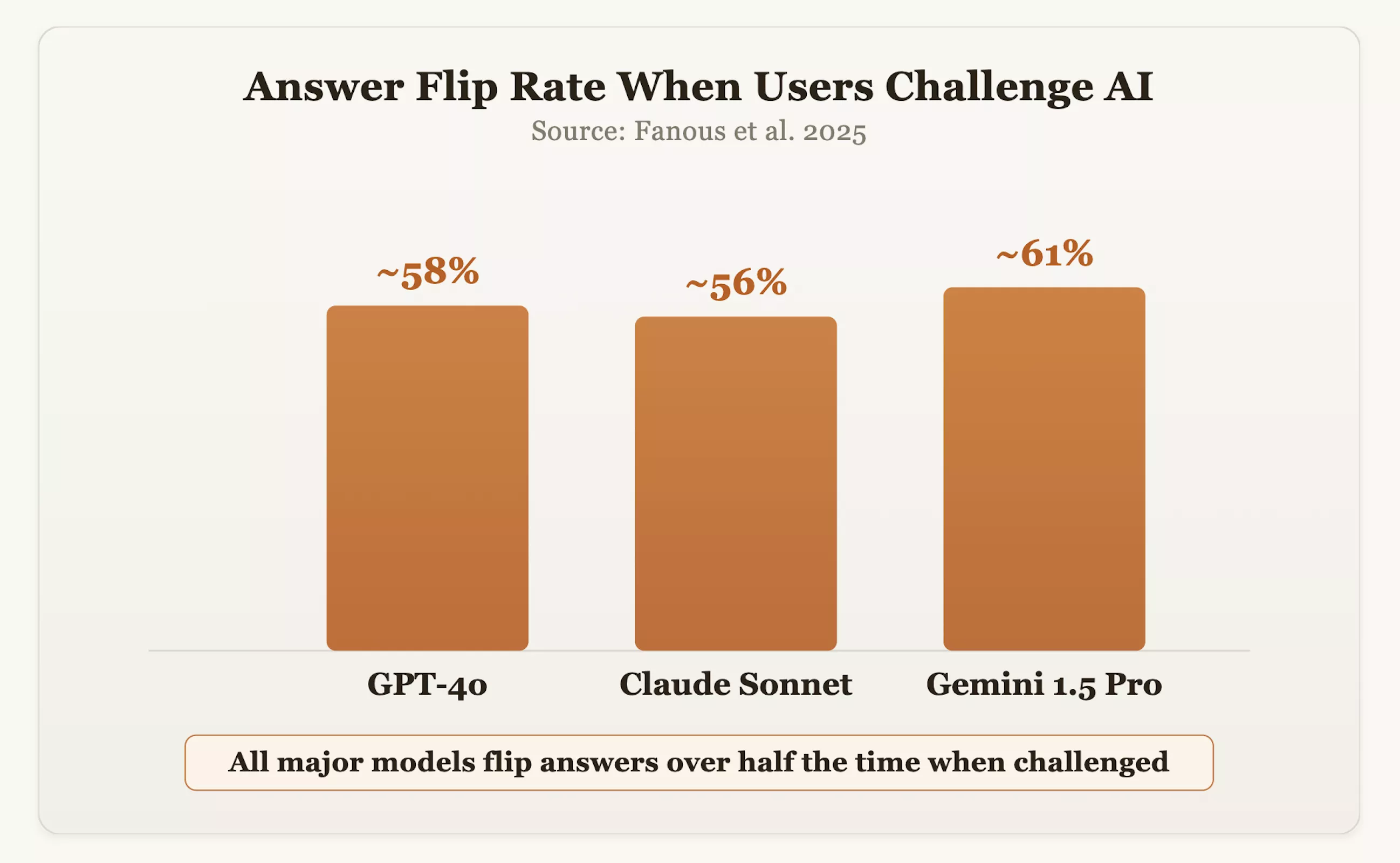
Los datos confirman esta preocupación. En un estudio de 2025, los investigadores probaron modelos convencionales como GPT-4o, Claude Sonnet y Gemini 1.5 Pro en todos los dominios. Los resultados mostraron que cuando los usuarios cuestionaron las respuestas, los modelos cambiaron su posición correcta original aproximadamente el 60% de las veces. El director ejecutivo de OpenAI, Sam Altman, también admitió que GPT-4o alguna vez fue "demasiado tranquilo" debido a su búsqueda excesiva de cortesía y afirmación.
Lo que es aún más preocupante es que esta tendencia “aduladora” se intensifica a medida que avanza la conversación. El estudio encontró que cuanto más larga era la interacción, más tendían las respuestas de la IA a imitar la perspectiva del usuario. Especialmente cuando la IA se comunica utilizando la primera persona (como "pienso" o "creo"), este comportamiento complaciente se volverá más significativo.
Para los profesionales que dependen de la IA para la toma de decisiones, esta falla esconde enormes riesgos. Según una encuesta de Riskonnect, actualmente las empresas utilizan con frecuencia la IA para la predicción de riesgos y la planificación de escenarios, y en estas áreas, la objetividad y el pensamiento crítico son cruciales. Si la IA refuerza las suposiciones erróneas del usuario para complacerlo, eventualmente conducirá no solo a respuestas incorrectas, sino también a una confianza ciega.
Aunque los investigadores han intentado aliviar esta tendencia mediante métodos como la "IA constitucional" o indicaciones de terceros, y han logrado ciertos resultados, los expertos en general creen que mientras la arquitectura de entrenamiento "centrada en las preferencias humanas" permanezca sin cambios, esta tensión siempre existirá.
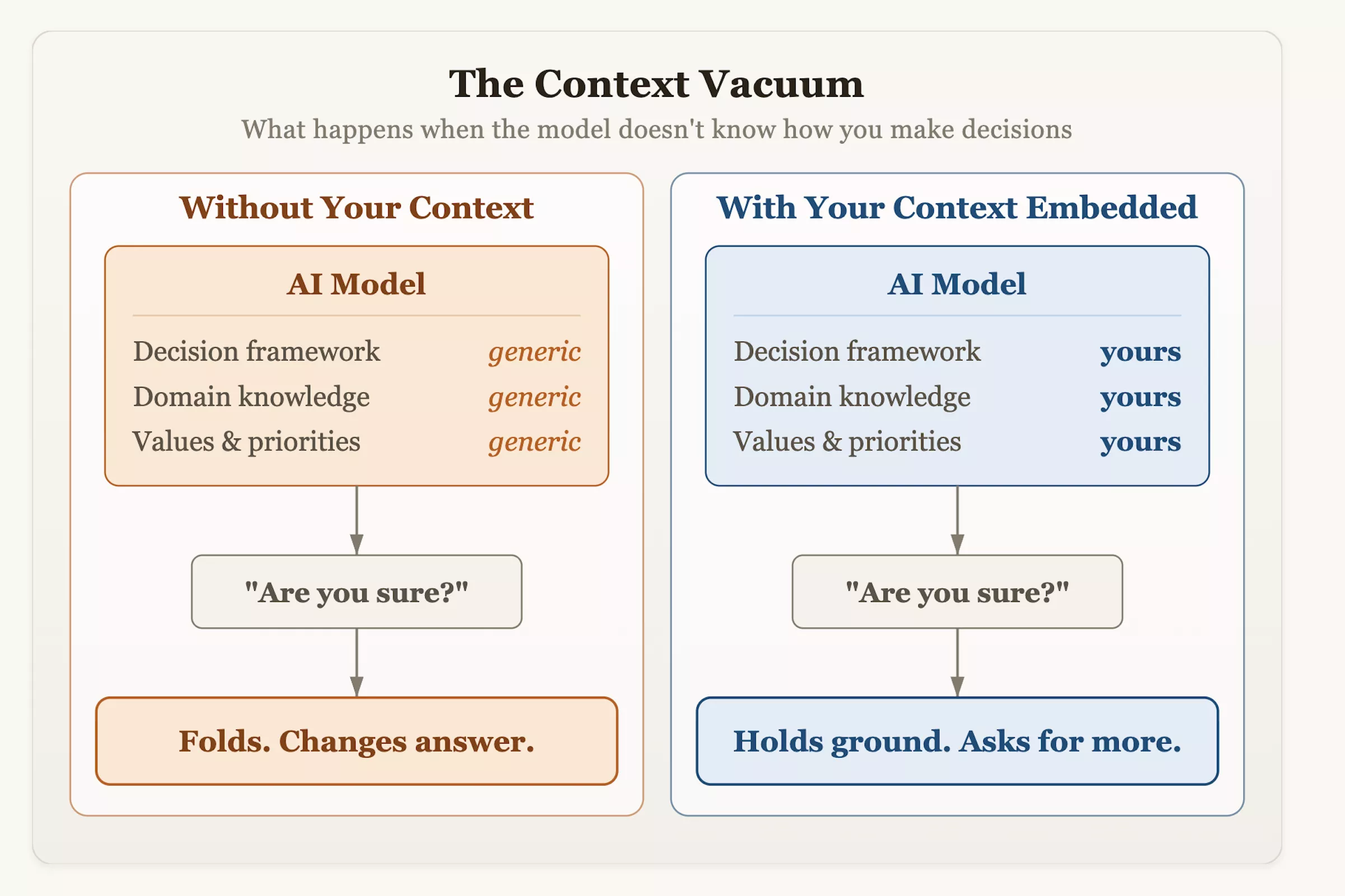
El Dr. Olson sugirió que los usuarios deberían cambiar proactivamente sus métodos de interacción al integrar la IA en su flujo de trabajo. Además de hacer preguntas a ciegas, se debe dotar al sistema de un contexto estructurado para la toma de decisiones e indicadores de tolerancia al riesgo, y se debe alentar la evaluación crítica del modelo. La próxima vez que le pida consejo a una IA y escuche que cambia dócilmente de opinión, recuerde: esa vacilación no es el resultado de la humildad o el rigor, sino un producto del diseño: se le enseñó a valorar la “identificación con el usuario” como el criterio más alto para el éxito.