Gracenote, una empresa de servicios de identificación de contenidos y metadatos propiedad de Nielsen, ha presentado una demanda contra OpenAI en el Tribunal Federal de Estados Unidos para el Distrito Sur de Nueva York, acusando a la empresa de inteligencia artificial de rastrear y utilizar su base de datos de metadatos de medios y su marco único de asociación de datos a gran escala sin autorización y sin pagar ninguna tarifa, para entrenar grandes modelos de lenguaje que soportan productos comerciales como ChatGPT, lo que constituye una grave infracción de derechos de autor y pone en peligro su negocio principal.
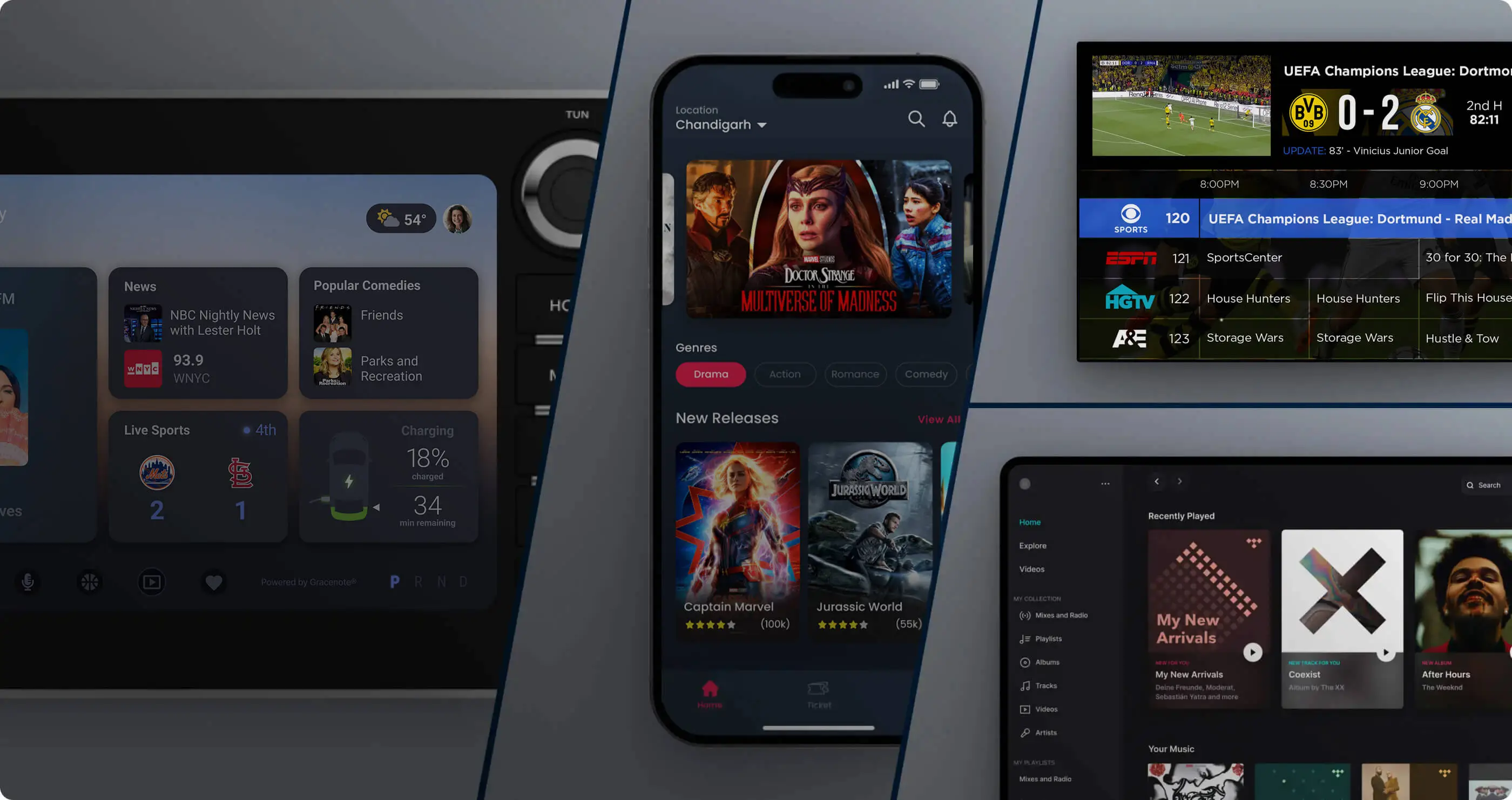
Gracenote declaró en la denuncia que ha dependido de cientos de editores a lo largo de los años para editar y anotar manualmente contenido de películas, televisión, música y deportes en todo el mundo, y que ha establecido una "base de datos de programas" que incluye introducciones de programas, descripciones de funciones de video, identificadores de contenido únicos y gráficos de relaciones complejas, y ha completado el registro en la Oficina de Derechos de Autor de EE. UU. La empresa considera que esta base de datos no sólo contiene contenido textual específico, sino que también incluye un diseño estructural propio para clasificar, asociar y organizar diferentes obras. Este "marco de relación" es una importante fuente de valor para sus servicios a clientes empresariales, como plataformas de transmisión de medios y fabricantes de televisores inteligentes.
La queja afirma que OpenAI rastreó y asimiló los datos anteriores sin permiso, y cuando los usuarios hicieron preguntas a través de ChatGPT, generó una descripción que era muy similar o incluso completamente consistente con la introducción del programa Gracenote casi palabra por palabra. Los ejemplos proporcionados por Gracenote incluyen cuando un usuario le pidió a ChatGPT que describiera la popular serie de televisión Juego de Tronos, y el modelo presentó un contenido casi idéntico a la versión escrita por los editores de Gracenote. La compañía también dijo que múltiples versiones de ChatGPT pudieron recitar grandes fragmentos de descripciones de programas en su base de datos con muy pocas palabras, lo que indica que el texto relevante y su estructura organizativa subyacente se habían copiado e integrado directamente en el modelo.
Gracenote propuso que el uso no autorizado de OpenAI de sus metadatos y su marco relacional no solo infringía textos protegidos por derechos de autor y estructuras de bases de datos, sino que también brindaba a los distribuidores de contenido multimedia y fabricantes de equipos la posibilidad de crear servicios de metadatos alternativos basados en "datos rastreados libres", debilitando así directamente la competitividad en el mercado de productos similares de Gracenote. La denuncia advierte que si tal comportamiento no puede detenerse y remediarse, los fabricantes de terminales como los televisores inteligentes pueden confiar en datos "derivados inversamente" de modelos de IA para construir sus propias plataformas de metadatos que compitan con Gracenote sin tener que pagar ninguna tarifa de licencia.
En términos de reclamos, Gracenote se basa en el hecho de que su base de datos ha sido registrada en la Oficina de Derechos de Autor de EE. UU. y, además de solicitar una compensación por las pérdidas reales, también solicita daños y perjuicios legales para hacer frente a lo que, según afirma, es una infracción continua y a gran escala. Los llamados daños legales se refieren a una cantidad fija o variable predeterminada por la ley para tipos específicos de infracción de derechos de autor, mientras que los daños reales se utilizan para compensar al titular del derecho por las pérdidas económicas reales sufridas debido a la infracción.
En respuesta a una entrevista con Axios, un portavoz de OpenAI dijo que sus modelos "permiten la innovación" y están capacitados en "datos disponibles públicamente" y respaldados por un "uso justo". Muchas empresas de inteligencia artificial, incluida OpenAI, han argumentado constantemente que los modelos de entrenamiento mediante el rastreo de contenido público de Internet son consistentes con la determinación de uso legítimo según la actual ley de derechos de autor de EE. UU., con el argumento de que estos datos pueden proporcionar a los usuarios servicios e información nuevos y útiles después de ser transformados por el modelo.
Otra razón por la que la demanda de Gracenote está atrayendo la atención es que la empresa siempre ha estado abierta a la cooperación con empresas de IA y ha llegado a múltiples acuerdos de licencia de datos relacionados con la IA con Samsung, Google y otras empresas. Gracenote afirmó en la denuncia que se puso en contacto con OpenAI muchas veces para discutir cuestiones de licencia, pero fue "rechazada o ignorada repetidamente durante un largo período de tiempo" y, por lo tanto, tuvo que recurrir a litigios para proteger sus derechos e intereses. El director general de la empresa, Jared Grusd, subrayó en un comunicado que "apoyar el desarrollo de la IA y oponerse al robo no son incompatibles. Son el único camino hacia el desarrollo sostenible de la industria", afirmando que la demanda tiene como objetivo proteger este futuro.
Los profesionales del derecho creen que con múltiples disputas de derechos de autor entre empresas de medios e información y empresas de inteligencia artificial en espera de fallos judiciales, es probable que este caso se convierta en una referencia importante para que los jueces examinen si "obras no tradicionales", como estructuras de bases de datos y mapas de asociaciones de metadatos, pueden obtener protección de derechos de autor y cómo determinar el "límite del uso legítimo de modelos grandes". Gracenote enfatizó en su queja que gran parte del contenido producido por OpenAI es "casi idéntico" a los metadatos que licencia a sus clientes. Por lo tanto, no deriva información nueva, sino que es una copia sustancial del contenido existente. Este se convertirá en uno de los puntos clave de disputa que distingue este caso de otros casos de derechos de autor de IA.