El 27 de junio, DeepSeek publicó el informe técnico de DSpark y el código base de DeepSpec. El modelo base de DeepSeek-V4 no ha cambiado. Lo nuevo es un módulo de decodificación especulativa del lado del servidor: DSpark. DeepSeek lo expresa muy claramente en la página del modelo HuggingFace: V4-Pro-DSpark y V4-Flash-DSpark "no son modelos nuevos". Estas dos páginas apuntan al mismo punto de control del modelo, más la versión del servicio después de especular sobre el módulo decodificado.

Esto significa que DSpark no hace que el modelo sea repentinamente más inteligente. Su objetivo es cómo generar respuestas de forma más rápida y económica una vez que el modelo esté en línea.
El informe técnico indicó que DSpark se implementó en el sistema de servicio en línea de DeepSeek-V4. Bajo el tráfico de usuarios reales, en comparación con la línea base de producción MTP-1 anterior, que es la solución de generación de especulación en línea de la generación anterior de DeepSeek, la velocidad de generación por usuario de V4-Flash aumenta entre un 60% y un 85%, y V4-Pro aumenta entre un 57% y un 78%, siempre que coincidan las condiciones de rendimiento.
El "rápido" aquí también debe moderarse.Se refiere principalmente a la etapa de generación, es decir, la velocidad a la que el modelo continúa generando tokens. Esto no significa que el tiempo de respuesta de un extremo a otro de todas las solicitudes de los usuarios sea un 85% más rápido.El llenado previo de palabras largas, la recuperación, la invocación de herramientas, las colas y los retrasos en la red seguirán afectando el tiempo que los usuarios realmente esperan.
Una vez que el modelo está en línea, todavía hay una cuenta de inferencia.
Esto no es tan animado como el lanzamiento de un nuevo modelo, pero se acerca más a la realidad a la que se enfrentan las empresas de IA todos los días:El costo no termina después de entrenar el modelo.
Los chatbots, asistentes de código, agentes y productos basados en búsquedas siguen consumiendo tiempo de GPU con cada llamada. Si el modelo es más lento, los usuarios tendrán que esperar más; Si la inferencia es más cara, será más difícil para los fabricantes abrir modelos de alta calidad a más escenarios.
La industria de la IA se ha acostumbrado más a discutir los costos de capacitación en los últimos dos años: cuántas GPU necesita comprar una empresa, qué tamaño de clúster debería construir y cuánto costará entrenar el modelo de próxima generación. Pero después de que el modelo se convierta realmente en un producto, seguirá apareciendo otro tipo de costo: la inferencia.
La formación es como un gran proyecto y el razonamiento es como una factura de servicios públicos.Mientras los usuarios sigan haciendo preguntas, los agentes sigan ejecutando tareas y los asistentes de código sigan generando parches, el modelo seguirá consumiendo potencia informática.
Los servicios de modelos grandes eventualmente volverán a dos indicadores: velocidad y costo unitario del token. Las páginas de precios de API generalmente cobran en función de los tokens de entrada y de salida, y las empresas también dividirán internamente diferentes modelos, cachés, rutas y longitudes de contexto en elementos de costo.
DSpark no se puede equiparar directamente con una reducción de precio, pero si el mismo clúster de GPU puede permitir a los usuarios obtener respuestas más rápido con un rendimiento similar, significa que el mismo hardware puede servir a más usuarios o se puede proporcionar la misma experiencia de usuario con menos tarjetas.
"Adivina primero y luego prueba"
La idea de decodificación especulativa puede entenderse aproximadamente como "primero adivinar y luego probar".
Cuando un modelo grande genera texto, generalmente escupe token tras token. Después de que salga la ficha anterior, la siguiente ficha sabrá qué recoger. Este método es estable pero lento. La decodificación especulativa permitirá que un módulo de borrador más liviano adivine un token candidato por adelantado, y el modelo grande objetivo se verificará en lotes. La suposición correcta se acepta directamente y la suposición incorrecta se corrige.
Los modelos pequeños no pueden tomar decisiones para los modelos grandes. El modelo de destino aún verifica qué tokens se aceptan finalmente; cuando se implementa correctamente, cambia el método de generación y no cambia la distribución de salida del modelo objetivo.La aceleración proviene de que modelos grandes validen candidatos en lotes, en lugar de hacerlo de forma incremental.
Lo que DSpark cambió es cómo generar un borrador.
El artículo no se detiene en la explicación de "primero adivinar y luego probar". Se centra en cómo generar borradores.

Los proyectos de estrategias existentes se dividen en términos generales en dos categorías. El redactor autorregresivo es más estable porque el token posterior verá el token anterior, pero a medida que el borrador se hace más largo, la demora también aumentará. El redactor paralelo es más rápido y puede adivinar un párrafo completo a la vez, pero cada posición se adivina por separado. Los tokens posteriores se desconectan fácilmente de los anteriores y es más probable que la tasa de aceptación disminuya a medida que avanza.
DSpark elige hacer concesiones.La palabra clave en el título del artículo es "Generación semiautoregresiva". Primero utiliza un método paralelo para proponer un candidato y luego utiliza una capa secuencial ligera para modificar la relación condicional de los tokens posteriores. Esto no sólo conserva la velocidad de la generación paralela, sino que también permite a los candidatos posteriores ver lo que se ha adivinado anteriormente.

Otro punto clave es la duración de la verificación.
Cuantas más fichas candidatas adivines, menos ahorrarás. Si sabe que es probable que la segunda mitad sea rechazada y aun así se la entrega a un modelo grande para su verificación, está gastando tiempo de GPU en una posición de bajo valor.DSpark observará la confianza del candidato y la carga actual del sistema para determinar dinámicamente la duración de la verificación.Si la GPU está vacía, puedes realizar varias pruebas; cuando la carga es alta, la potencia de cálculo se reserva para las piezas que tienen más probabilidades de ser aceptadas.
De esto es de lo que habla el "Programado de confianza" en el título del artículo.

DSpark se encuentra en rutas técnicas existentes
DSpark se mantiene firme después de especular sobre la ruta de decodificación existente, y es más como una referencia pública después de que DeepSeek impulse esta ruta técnica a los servicios en línea.
SpecInfer incorporó la predicción de modelos pequeños, el árbol de tokens y la verificación paralela al sistema de servicios de modelos grandes a partir de 2023; Medusa propuso agregar múltiples cabezales de decodificación al modelo en 2024 para predecir múltiples tokens posteriores a la vez; La serie EAGLE continúa mejorando la tasa de aceptación en torno a modelos de borrador y árboles de borrador dinámicos. Los marcos de inferencia como vLLM, SGLang y TensorRT-LLM han considerado durante mucho tiempo la decodificación especulativa como una herramienta importante para reducir la latencia.
La ventaja de DSpark es que maneja varios problemas de producción juntos: cómo generar borradores, cómo mantener la coherencia de los candidatos, cómo cambia la duración de la verificación con la carga y cuánto se puede mejorar la velocidad con tráfico real en línea.
Las palabras clave que aparecen repetidamente en el documento también han pasado de "mejora de la capacidad del modelo" a términos del lado del servicio, como velocidad de generación por usuario, rendimiento coincidente y acuerdo de nivel de servicio (SLA).
Esto también explica por qué no puedes simplemente elegir el número más grande para mirar. De hecho, hay datos de alto rendimiento como 661% y 406% en el documento, pero provienen de objetivos de velocidad por usuario más estrictos: bajo esa configuración, la antigua línea de base en sí ya está cerca del límite de las capacidades del servicio, y la ventaja relativa de DSpark se amplificará.
Lo que realmente puede ilustrar los beneficios normales es el conjunto de números anterior: rendimiento coincidente, distribución del tráfico real y el objeto de comparación es MTP-1.
¿Qué puede reproducir DeepSpec?
DeepSeek también es DeepSpec de código abierto. Esta es una biblioteca de códigos para entrenar y evaluar borradores de modelos de decodificación especulativa. Incluye procesos de preparación, capacitación y evaluación de datos, y también publica puntos de control relevantes en Qwen3, Gemma y otros modelos.
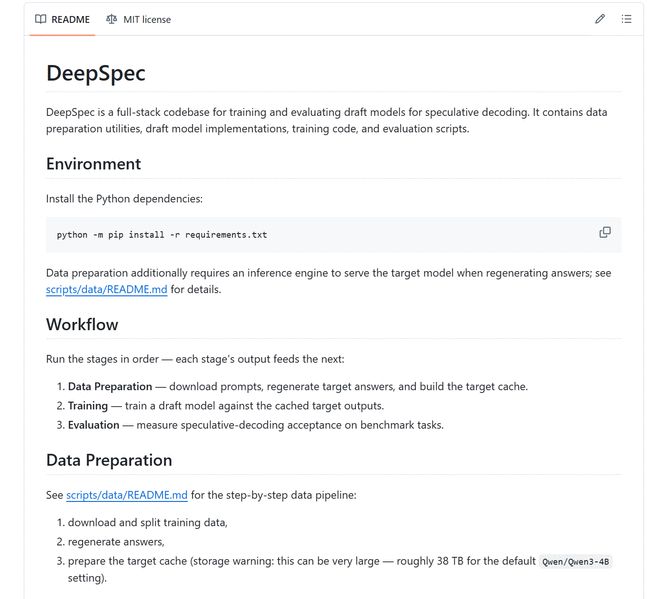
pero,Código abierto no significa "descargar y reproducir".La documentación del proyecto indica que bajo la configuración predeterminada de Qwen3-4B, el caché del modelo de destino puede estar cerca de 38 TB; el script de entrenamiento predeterminado supone 8 GPU en un solo nodo; Si los resultados en papel deben estar alineados, la configuración de capacitación debe ser estrictamente consistente y se requiere un ajuste adicional del modelo borrador en áreas específicas.
El mundo exterior puede verificar parte del método y también puede trasplantar DeepSpec a otros modelos de código abierto, pero el conjunto de cifras de mejora de velocidad en el servicio en línea DeepSeek-V4 aún proviene de la escala de hardware, la distribución del tráfico y la programación del sistema de producción de DeepSeek.
El código abierto es el método, no el entorno.
La comunidad está más preocupada por los límites recurrentes.
La discusión sobre
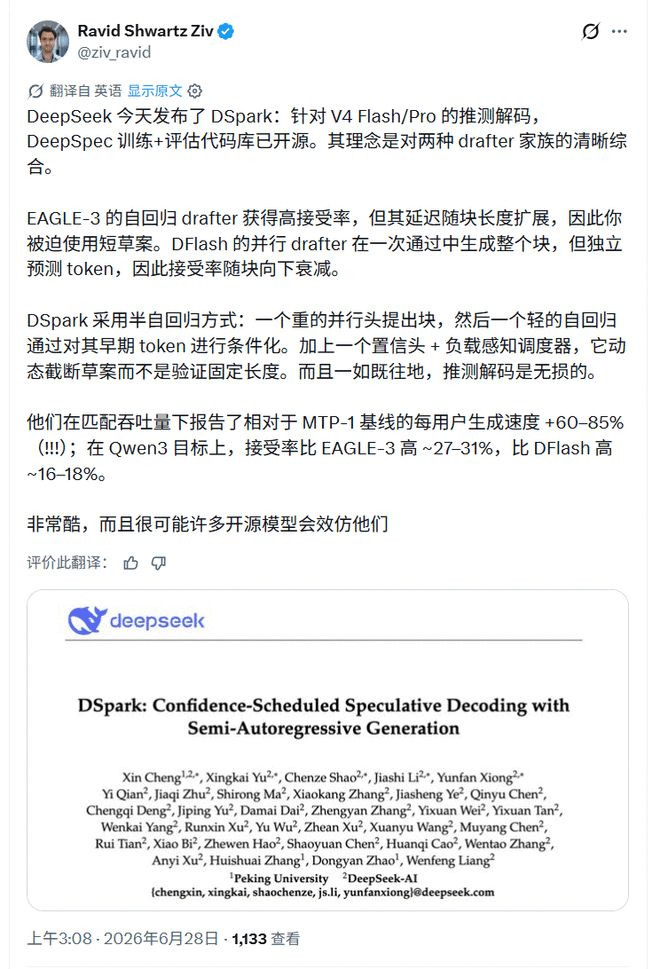
El investigador de IA Ravid ShwartzZiv resume DSpark como un compromiso entre dos tipos de redactores: el redactor paralelo es rápido, pero la tasa de aceptación decae a lo largo del bloque de candidatos; el redactor autorregresivo es estable, pero el retraso aumenta con la duración del borrador. Mencionó específicamente dos componentes agregados a DSpark: el cabezal de juicio de confianza y el programador consciente de la carga, y agregó un límite clave: "Como toda decodificación especulativa, no tiene pérdidas".
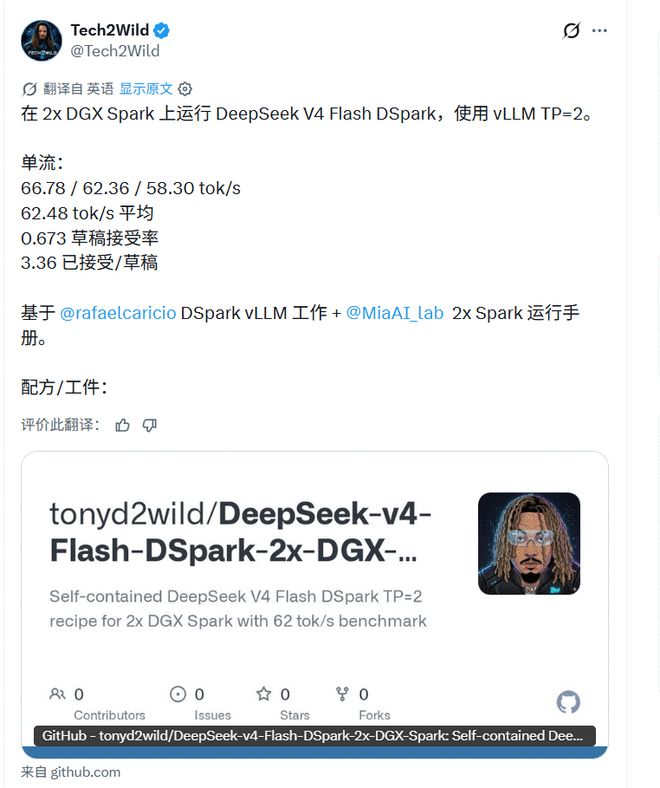
Los ingenieros están más preocupados por si puede funcionar. Rafael Caricio, colaborador de vLLM, dijo que ejecutó el modo DSpark de DeepSeek-V4-Flash en DGX Spark GB10 dual y que la decodificación de flujo único fue de aproximadamente 60 tok/s, que es aproximadamente 1,5 veces mayor que la de MTP-1.
También mencionó que la sesión de código real expuso problemas que los puntos de referencia sintéticos no pudieron ver: el cuello de botella no es solo la velocidad del núcleo informático, sino que la tasa de aceptación del borrador caerá significativamente en un contexto prolongado.
Tech2Wild también proporcionó datos in situ en una dirección similar, mostrando que V4-Flash-DSpark ha sido probado en un entorno vLLM específico. Sin embargo, dichos resultados dependen en gran medida del modelo de hardware, la versión del parche del marco, la longitud del contexto y la configuración de simultaneidad. Los resultados pueden ser completamente diferentes en otro entorno.
También hay personas que te recuerdan específicamente los límites. AcingAI señaló en
Esto nos recuerda que parte de la ventaja de DSpark proviene de la programación consciente de la carga, y el efecto de la programación depende naturalmente de la escala del tráfico y la configuración del hardware del entorno de producción.
Misma potencia, menos potencia informática
En un informe del 28 de junio, el South China Morning Post analizó DSpark en términos de cuellos de botella de inferencia, presión del chip y tiempo de espera del usuario. Esta perspectiva está más cerca de la realidad del producto que "¿Qué modelo lanzó DeepSeek nuevamente?"
Las empresas de IA seguirán comparando las capacidades de los modelos, pero cuando la brecha de capacidades se reduzca, quién pueda ofrecer las mismas capacidades más rápido y más barato también pasará a formar parte de la competencia.
Empresas como DeepSeek necesitan especialmente dejar esto claro. DeepSeek siempre ha considerado el bajo costo y la alta eficiencia como un punto de entrada importante para que el mundo exterior lo entienda. Desde la narrativa del entrenamiento del modelo hasta el precio de la API, lo que más llama la atención no es si tiene una escala de parámetros mayor, sino si puede abaratar las mismas capacidades.
DSpark continúa esta línea: no prueba que V4 sea de repente más inteligente, demuestra que V4 puede desperdiciar menos potencia informática de razonamiento al atender a los usuarios.
Si ampliamos un poco más nuestra perspectiva, la optimización de la inferencia también afectará la ecología del modelo de código abierto. El modelo de código abierto solía considerarse "barato", pero cuando realmente se implementa, la memoria gráfica, el rendimiento, la concurrencia, la latencia y la complejidad de operación y mantenimiento se convertirán en costos.
Si un modelo puede ser de código abierto, sólo significa que todos pueden obtenerlo; Que pueda servir a un gran número de usuarios de forma económica depende de si la pila de inferencia puede mantenerse al día.
DeepSpec lanzó Qwen3, Gemma y otros puntos de control, lo que indica que este asunto no termina con DeepSeek-V4. El alcance de la migración depende del progreso real de la adaptación de la comunidad, el soporte del marco y la compatibilidad del hardware; pero a juzgar por la información pública actual, DeepSeek ha tomado esta ruta fuera de su propio modelo.
El valor de DSpark radica aquí.Agrega una capa de herramientas de servicio de inferencia a V4 que está más cerca del sistema de producción, en lugar de simplemente una nueva etiqueta de capacidad.
Lo que vale la pena observar a continuación no es sólo qué tan rápido puede ejecutar DeepSeek, sino también cuántas personas pueden pasar por esta ruta. DeepSpec ha publicado puntos de control y procesos de capacitación, y se especula que la decodificación está pasando de ser una elección de ingeniería de una empresa a un medio común de inferencia de código abierto para reducir costos.Eso supone que otros marcos y hardware puedan seguir el ritmo.