AMD está promoviendo una visión de inteligencia artificial que no depende de la nube. Su marco OpenClaw recientemente lanzado, junto con dos conjuntos de configuraciones de referencia de hardware, RyzenClaw y RadeonClaw, está diseñado para permitir a los desarrolladores y a los primeros usuarios ejecutar grandes modelos de lenguaje y flujos de trabajo de múltiples agentes en PC locales. Esta medida es parte del plan más amplio "Agent Computer" de AMD, que cree que el futuro de la IA no debería limitarse a los centros de datos remotos, sino que debería dar a los usuarios el control de sus propios datos y entorno informático, mantener los asistentes de IA locales en funcionamiento durante mucho tiempo, reducir las dependencias de la red y las cargas de suscripción, y aliviar las preocupaciones sobre la privacidad.

Desde una perspectiva técnica, OpenClaw actualmente se ejecuta en la plataforma Windows a través de WSL2 (Subsistema de Windows para Linux 2), y LM Studio se utiliza con el backend llama.cpp para realizar tareas de inferencia local. En este entorno, los usuarios pueden ejecutar modelos como Qwen 3.5 35B A3B directamente en la máquina. El sistema también admite un marco de memoria integrado llamado Memory.md para almacenar información contextual localmente sin depender de la sincronización en la nube. AMD posiciona el tutorial oficial como una ruta de configuración relativamente simplificada para facilitar a los desarrolladores crear un entorno OpenClaw completo en Windows y probar la arquitectura del agente de IA, pero el documento no proporciona un tiempo de configuración estimado claro.

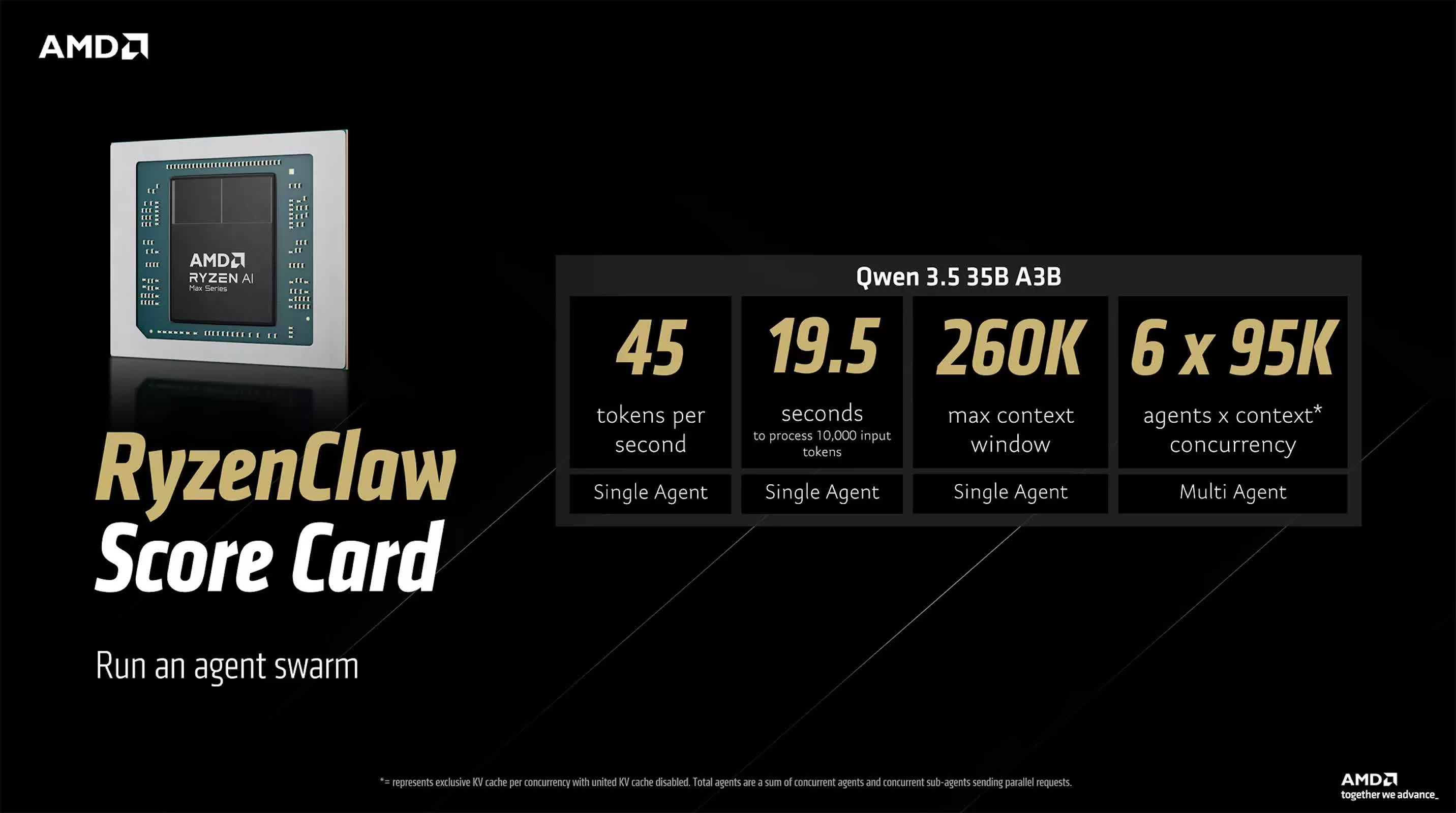
Las dos referencias de OpenClaw propuestas por AMD representan diferentes rutas hacia la "IA nativa de alto rendimiento". La solución RyzenClaw se basa en el procesador Ryzen AI Max+ y está equipada con 128 GB de memoria unificada, de los cuales AMD recomienda que se asignen aproximadamente 96 GB como memoria de video variable para garantizar una eficiencia de inferencia de modelos grandes. Bajo esta configuración, Qwen 3.5 35B A3B genera aproximadamente 45 tokens por segundo, tarda aproximadamente 19,5 segundos en procesar una entrada de 10 000 tokens, admite una ventana de contexto de aproximadamente 260 000 tokens y se puede usar en flujos de trabajo de múltiples agentes o entornos experimentales de "grupo de agentes". AMD dice que la plataforma puede ejecutar hasta seis agentes de IA locales simultáneamente, lo cual es típico de sistemas que no son de nivel de centro de datos.

Otra configuración de RadeonClaw cambia el foco de la potencia informática a la GPU independiente: Radeon AI PRO R9700. Esta tarjeta gráfica de estación de trabajo ofrece 32 GB de memoria gráfica dedicada, lo que aumenta significativamente el rendimiento de inferencia. Con el mismo modelo, la velocidad de generación se puede aumentar a unos 120 tokens por segundo, acortando el tiempo para procesar una entrada de 10.000 tokens a unos 4,4 segundos. Sin embargo, esta ganancia de rendimiento conlleva ciertas compensaciones: la ventana de contexto máxima se reduce a aproximadamente 190 000 tokens y el número de agentes concurrentes se reduce a 2. Estas diferencias resaltan el intento de AMD de proporcionar diferentes rutas de ajuste que permitan a los desarrolladores intercambiar una mayor profundidad de contexto y una inferencia más rápida según sus necesidades.
En términos de posicionamiento, ni RyzenClaw ni RadeonClaw son configuraciones básicas para consumidores comunes. Tomando RyzenClaw como ejemplo, una computadora de escritorio basada en el chip Ryzen AI Max+ 395 y equipada con 128 GB de memoria (como el plan Framework Desktop) comienza en aproximadamente $ 2700. Si sigue la ruta RadeonClaw, también necesitará comprar la tarjeta gráfica Radeon AI PRO R9700, que por sí sola tiene un precio minorista sugerido de aproximadamente $1,299. AMD actualmente admite que los principales usuarios objetivo de OpenClaw son ingenieros y primeros usuarios que están experimentando con agentes de IA locales, en lugar de usuarios de PC convencionales.

Aún así, el mensaje de OpenClaw va más allá del hardware específico en sí. AMD está apostando por una tendencia en la que los desarrolladores valorarán la autonomía y la privacidad por encima de la expansión a escala de la nube, con la esperanza de construir un puente entre la informática personal y la IA distribuida a través de agentes locales que se ejecutan en chips de consumo. Si el ecosistema reconoce esta idea, se espera que AMD ocupe una posición única en el panorama de la IA en rápida evolución, permitiendo que algunas computadoras de escritorio y estaciones de trabajo de alta gama tengan gradualmente capacidades de procesamiento de IA cerca de los centros de datos, manteniendo al mismo tiempo una sensación de control y flexibilidad por parte del usuario.