Según el Wall Street Journal, el campo de la IA está experimentando un cambio importante, que tendrá un profundo impacto en las empresas de tecnología, grandes y pequeñas.Durante los últimos cinco años, el foco principal en el campo de la IA ha sido el entrenamiento de grandes modelos de lenguaje. Se trata de un proceso costoso que requiere decenas de miles de chips, consume enormes cantidades de energía y se lleva a cabo en grandes centros de datos remotos.Este proceso de capacitación requiere el uso de un grupo de miles de chips de microprocesadores especializados para introducir miles de millones de datos (como definiciones de palabras, hechos históricos, estadísticas financieras, fotografías de gatos, etc.) en el modelo. Los grupos de chips funcionan las 24 horas del día, los 7 días de la semana durante semanas o incluso meses.

Figura 1: Huang Renxun comenzó a centrarse en los chips de inferencia
Del entrenamiento a la inferencia
Ahora, a medida que más empresas implementan agentes de IA e intentan comercializar nuevas herramientas basadas en grandes modelos de lenguaje, la atención se ha centrado en la inferencia: el tipo de computación que permite que los modelos de IA entrenados respondan a las consultas de los usuarios.
Según datos de la firma de investigación Gartner, se espera que los gastos de capital globales en infraestructura de inferencia (incluidos chips, centros de datos y hardware de red) superen los gastos de capital en capacitación por primera vez este año. Para 2029, las empresas gastarán 72 mil millones de dólares en inferencia, casi el doble de los 37 mil millones de dólares gastados en capacitación.
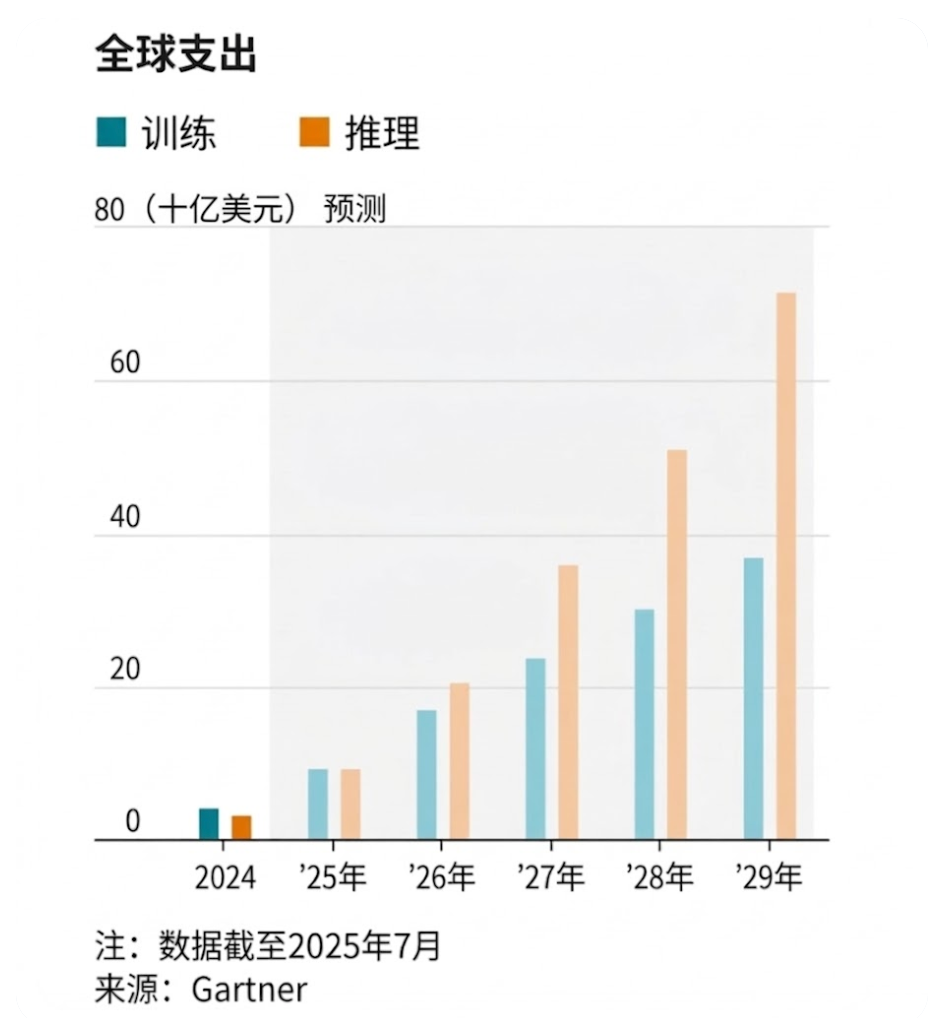
El gasto en inferencia superará la formación
El cambio significa cambios importantes en los tipos de chips que compran las empresas de tecnología. Nvidia se ha convertido en la empresa más valiosa del mundo gracias a la venta de chips llamados GPU, que proporcionan la potencia de procesamiento bruta necesaria para el entrenamiento de modelos.Pero Jacob Feldgoise, un académico que estudia IA en la Universidad de Georgetown, dijo que las empresas que esperan hacer más trabajo de inferencia pueden obtener ganancias de rendimiento utilizando chips optimizados para tareas de inferencia.
Entre los fabricantes especializados en chips de inferencia se encuentran Google, Cerebras Systems, SambaNova, etc., y están firmando pedidos por valor de miles de millones de dólares a un ritmo cada vez mayor. NVIDIA se está preparando para lanzar su propio procesador específico de inferencia después de gastar 20 mil millones de dólares en diciembre del año pasado para licenciar la tecnología de la empresa de chips de inferencia personalizados Groq y absorber sus mejores talentos.
Entonces, ¿qué es exactamente la computación inferencial? ¿En qué se diferencia del cálculo necesario para la formación? ¿Por qué la demanda pasó tan rápidamente al razonamiento? ¿Qué significa esto para el mercado?
Principios del cálculo inferencial
Puedes pensar en la IA como un restaurante. El modelo es el chef. Después de un período de formación intensiva, aprendiendo cientos o incluso miles de millones de recetas y técnicas de cocina, está listo para empezar a recibir pedidos.
El razonamiento es el día a día de este restaurante. El comensal hace un pedido (normalmente en forma de una pregunta al chatbot) y el chef prepara la comida (el chatbot genera una respuesta).
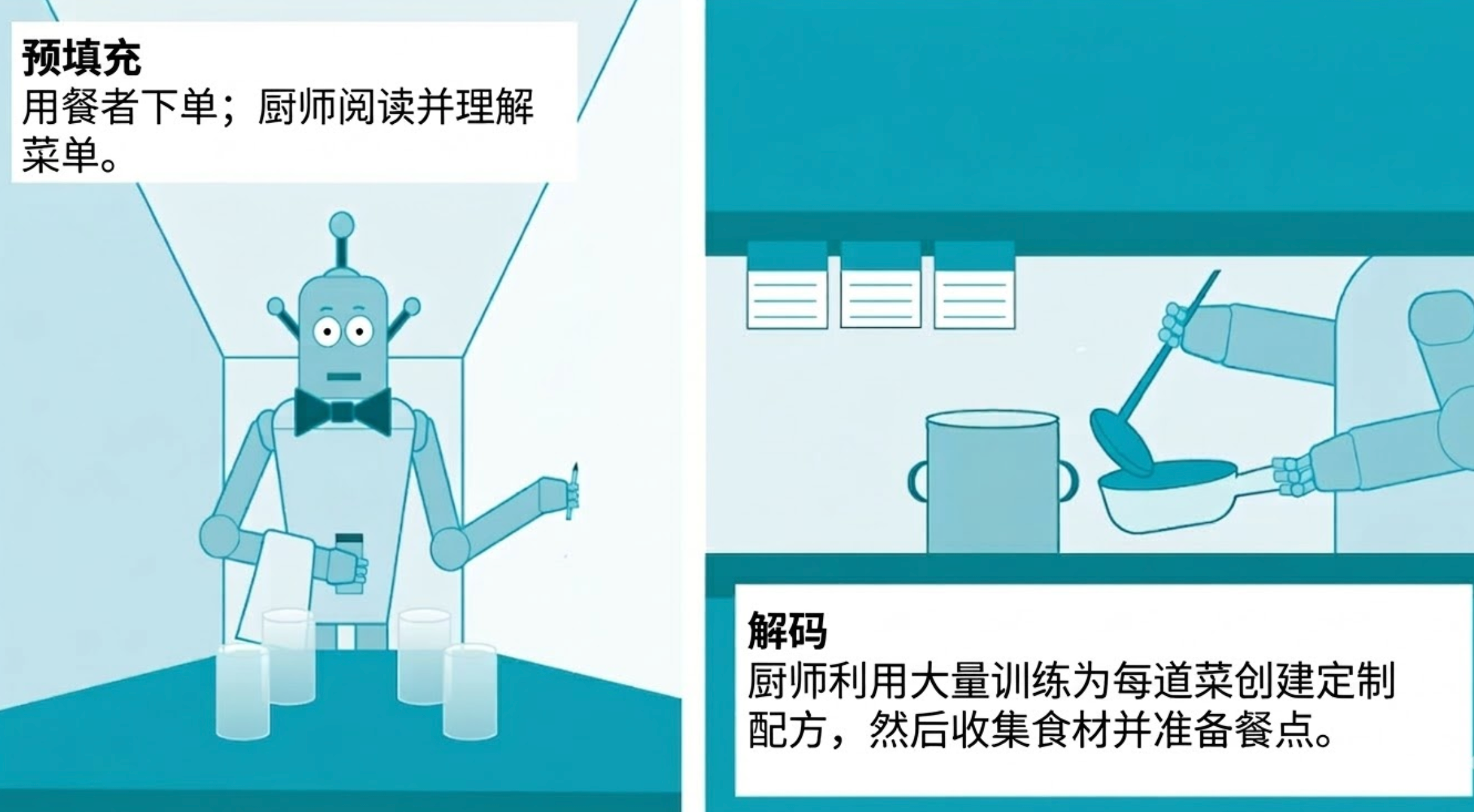
principios de razonamiento
La inferencia consta de dos etapas, prellenado y decodificación. Cuando el usuario ingresa la palabra solicitada, comienza la fase de llenado previo y el modelo interpreta la consulta del usuario procesando cada palabra, símbolo o imagen que contiene.
La decodificación es el proceso mediante el cual el modelo utiliza todo lo aprendido durante el entrenamiento para generar una respuesta a la consulta.
Estas dos etapas de inferencia tienen requisitos diferentes en el chip: la etapa de prepoblación requiere más potencia de procesamiento, mientras que la etapa de decodificación requiere más memoria, en parte porque debe movilizar todo el conocimiento acumulado para presentar nuevos "tokens" al usuario.
¿Qué son los elementos verbales?
Los tokens son las unidades básicas de datos que se utilizan para procesar consultas y generar respuestas.
Aunque los rangos de conversión correspondientes a diferentes tipos de datos varían, generalmente se cree que un elemento de palabra equivale aproximadamente a tres cuartos de una palabra en inglés. Realice una consulta simple de chatbot como "¿Cómo está el clima hoy?" Por ejemplo. El modelo lo analizará en seis a ocho tokens.
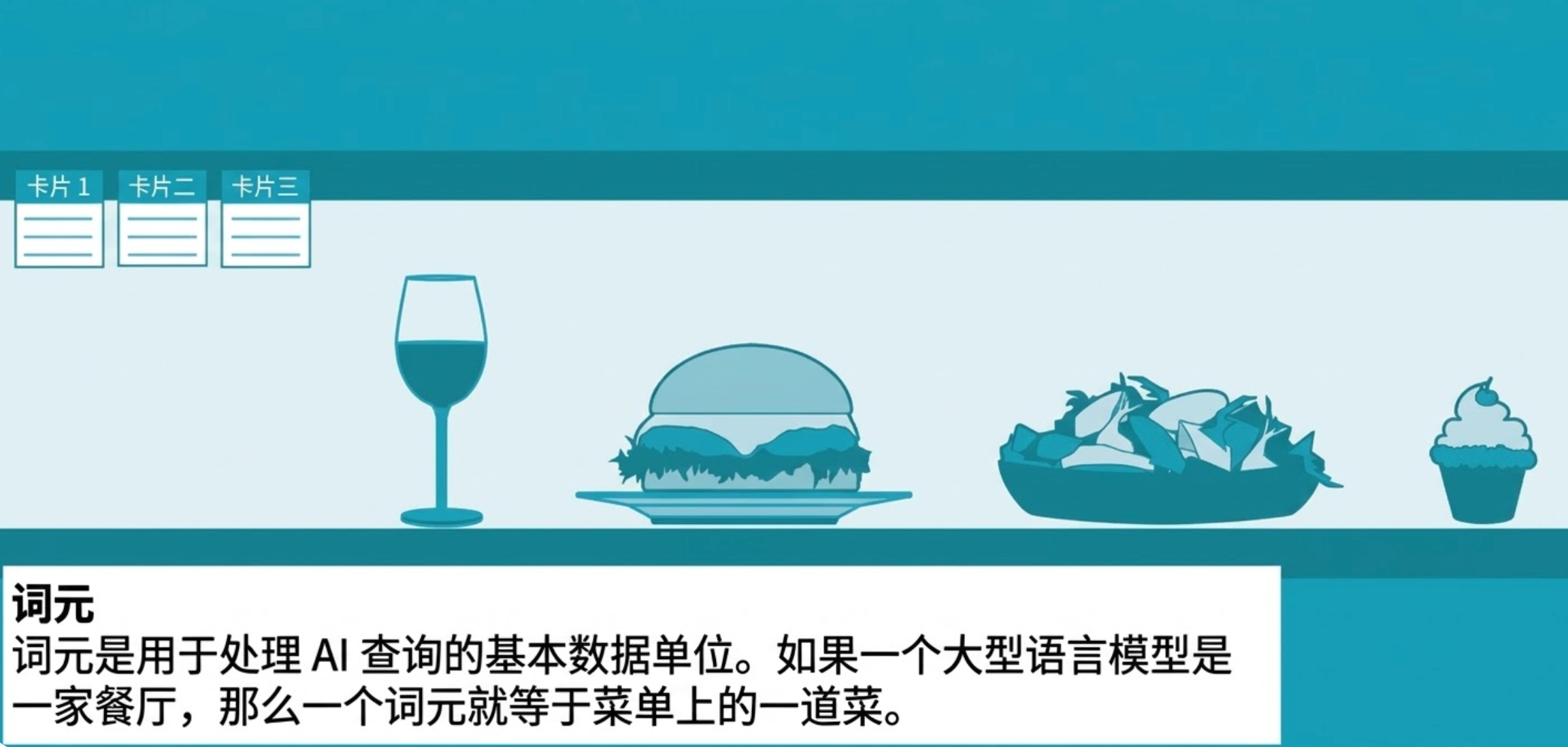
elemento de palabra
El modelo generalmente genera una unidad de palabras a la vez, y cada unidad de palabras debe generarse en el orden correcto para garantizar que la respuesta sea fluida y razonable.
Actualmente, las empresas que intentan monetizar las herramientas de inteligencia artificial, desde software de contabilidad hasta servicios de reserva de viajes y generadores de imágenes, están obsesionadas con métricas de costos como “palabras por segundo por vatio” o “palabras por segundo por dólar”.
Tim Breen, director ejecutivo del fabricante de chips GlobalFoundries, dijo que esto hace que la capacidad de los chips de inferencia para generar resultados de manera eficiente sea particularmente importante. "Hoy en día, la clave es reducir el coste de la inferencia".
La diferencia entre chips de entrenamiento y de inferencia.
Dado que la capacitación requiere el procesamiento de cantidades masivas de datos durante un largo período de tiempo, el chip utilizado debe tener potentes capacidades de procesamiento y el centro de datos donde se encuentra el chip debe tener acceso a suficiente energía y agua para enfriar el chip. El entrenamiento también requiere memoria, pero si la memoria de la GPU es insuficiente, algunas tareas de procesamiento se pueden asignar a otros chips o esperar a que se libere la memoria existente.
Por el contrario, el proceso de inferencia ocurre bajo demanda y toma segundos, no semanas. "Durante más de diez segundos, el usuario ya ha comenzado a tocar la pantalla del teléfono con el pulgar, listo para hacer lo siguiente". Dijo Rodrigo Liang, director ejecutivo de la empresa de diseño de chips SambaNova.
Por lo tanto, los chips de inferencia deben estar equipados con mayores capacidades de memoria de gran ancho de banda y sus centros de datos deben ubicarse cerca de los grupos de usuarios para reducir la latencia. Las nuevas empresas de chips como Ayar Labs también están recurriendo cada vez más a componentes de conectividad de fibra óptica, que pueden transmitir datos más rápido que los cables de cobre y requieren menos refrigeración.
"Hoy en día, todo se trata de escalar la inferencia", dijo el director ejecutivo de Ayar Labs, Mark Wade.