OpenAI lanzó el martes sus dos modelos pequeños más potentes hasta la fecha, GPT-5.4 mini y GPT-5.4 nano, reduciendo significativamente la brecha de rendimiento con los modelos emblemáticos con menor latencia y menor costo.GPT-5.4 mini supera a la generación anterior GPT-5 mini en dimensiones centrales como programación, razonamiento, comprensión multimodal e invocación de herramientas. La velocidad de carrera aumenta más de 2 veces y está cerca del GPT-5.4 más grande en pruebas de referencia como SWE-Bench Pro.
GPT-5.4 nano se posiciona como la opción liviana con el menor costo y la latencia más corta. Solo está abierto a desarrolladores a través de API y está diseñado para clasificación y extracción de datos y subtareas de programación simples.
El lanzamiento de los dos modelos tiene como objetivo llenar el vacío en el que los modelos grandes son difíciles de implementar en escenarios de interacción en tiempo real debido a grandes retrasos, lo que afecta directamente al mercado comercial en rápido crecimiento que cubre asistentes de programación, sistemas de agentes de IA y aplicaciones multimodales.
mini es para el consumidor y la API exclusiva de nano
GPT-5.4 mini se lanzará simultáneamente en los tres canales principales de OpenAI API, la plataforma Codex y ChatGPT a partir de hoy.
El precio API de GPT-5.4 mini es de 0,75 dólares estadounidenses por millón de tokens de entrada y de 4,50 dólares estadounidenses por millón de tokens de salida., admite entrada de texto e imágenes, llamada de herramientas, llamada de funciones, búsqueda web, recuperación de archivos, control de computadora y expansión de habilidades, y la ventana contextual alcanza los 400.000 tokens.
En la plataforma Codex, GPT-5.4 mini solo consume el 30% de la cuota de GPT-5.4, y el costo para los desarrolladores de manejar tareas de programación simples se reduce a aproximadamente un tercio del del modelo insignia.Codex también admite la delegación de cargas de trabajo a subagentes que se ejecutan en GPT-5.4 mini, lo que permite que las tareas menos intensivas en inferencia caigan automáticamente en modelos más baratos.
En el lado de ChatGPT, los usuarios de Free and Go pueden seleccionar la función "Pensamiento" a través del menú "+" para usar GPT-5.4 mini; para otros usuarios de pago, después de que GPT-5.4 Thinking alcance el límite de velocidad, este modelo se habilitará como una opción de degradación automática.
Actualmente, GPT-5.4 nano solo está disponible para desarrolladores a través de API y tiene un precio de 0,20 dólares por millón de tokens de entrada y 1,25 dólares por millón de tokens de salida, lo que lo convierte en el precio más bajo de los dos nuevos modelos. OpenAI declaró que nano es adecuado para escenarios de subagente coordinados y programados por modelos de alto orden y responsables del procesamiento de tareas de soporte secundarias.
mini se acerca al buque insignia, nano supera a la generación anterior
A juzgar por los datos de evaluación publicados por OpenAI, GPT-5.4 mini funciona particularmente bien en programación y tareas multimodales.
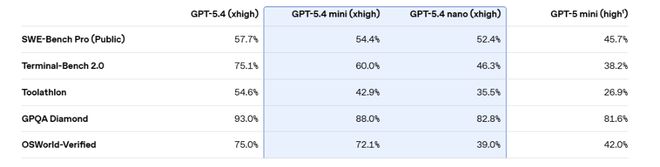
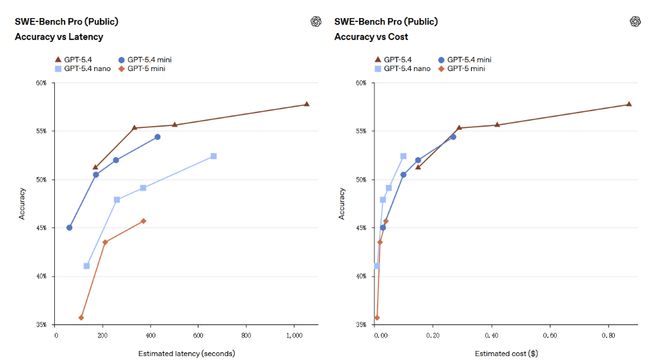
En el punto de referencia de programación SWE-bench Pro, mini obtuvo un 54,4%, y la brecha con el 57,7% de GPT-5.4 se redujo a 3,3 puntos porcentuales, mucho más alto que el 45,7% de GPT-5 mini.

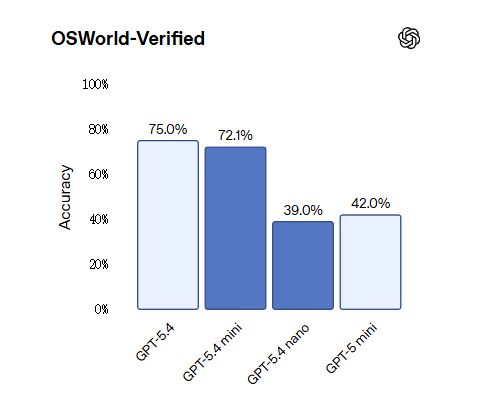
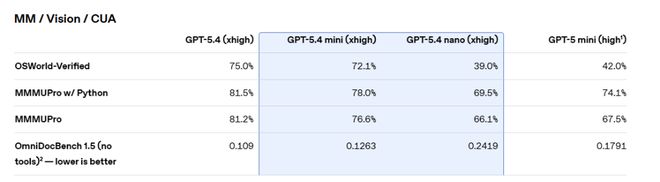
puntos de referencia controlados por computadoraEn OSWorld-Verified, mini se acerca al 75,0% de GPT-5.4 con un 72,1%, y está significativamente por delante del 42,0% de GPT-5 mini.
Capacidad de llamada de herramientas, GPT-5.4 mini obtuvo una puntuación del 93,4% en la prueba de telecomunicaciones de τ2-bench, una mejora significativa con respecto al 74,1% del GPT-5 mini. En la prueba de inteligencia general GPQA Diamond, el mini obtuvo una puntuación del 88,0% y el nano también alcanzó el 82,8%, superando ambos el 81,6% del GPT-5 mini.

Vale la pena señalar que GPT-5.4 nano va por detrás de GPT-5 mini en algunas tareas visuales, con una puntuación verificada por OSWorld de un 39,0% menor que el 42,0% de este último. Sin embargo, en términos de programación y tareas de llamada de herramientas, nano todavía ha mejorado significativamente en comparación con la generación anterior.
OpenAI afirmó que la prioridad del diseño nano es la baja latencia y el bajo costo, en lugar del rendimiento integral. Los desarrolladores deben hacer concesiones basadas en tareas específicas al seleccionar.
La arquitectura de subagentes y la colaboración multimodelo se convierten en un nuevo paradigma del diseño de productos
En sus materiales de lanzamiento, OpenAI enfatizó la posición de los dos nuevos modelos en el sistema jerárquico multimodelo.
Tomando como ejemplo su asistente de programación de desarrollo propio Codex, GPT-5.4 es responsable de la planificación, la coordinación y el juicio final, mientras que el mini subagente GPT-5.4 maneja subtareas más detalladas, como la recuperación de la base de código, la revisión de archivos grandes y el procesamiento de documentos auxiliares en paralelo.
OpenAI dijo que a medida que los modelos pequeños se vuelven más rápidos y poderosos, los desarrolladores ya no necesitan usar un solo modelo para manejar todas las tareas, sino que pueden construir sistemas donde los modelos grandes son responsables de la toma de decisiones y los modelos pequeños realizan tareas rápidamente y a escala.OpenAI dijo:
GPT-5.4 mini es nuestro modelo pequeño más potente hasta el momento para este flujo de trabajo.
Esta arquitectura es particularmente crítica para trabajos de alta concurrencia. En escenarios como asistentes de programación, análisis de capturas de pantalla y comprensión de imágenes en tiempo real, los retrasos en la respuesta afectan directamente la sensación del producto. La elección óptima a menudo no es el modelo con las mayores capacidades, sino el modelo que puede lograr el mejor equilibrio entre velocidad, confiabilidad de la herramienta y desempeño de la tarea.
Para los desarrolladores, el lanzamiento de GPT-5.4 mini y nano significa que el camino para reducir significativamente los costos de inferencia sin sacrificar la inteligencia general del sistema es aún más claro.