Hoy, Ant Bailing lanzó oficialmente Ling-2.6-flash, un modelo Instruct con un volumen total de parámetros de 104B y un parámetro de activación de 7.4B.Este modelo se centra en la "eficiencia del token". Si bien mantiene un nivel de inteligencia competitivo, es más rápido, más económico y más adecuado para aplicaciones reales a gran escala.
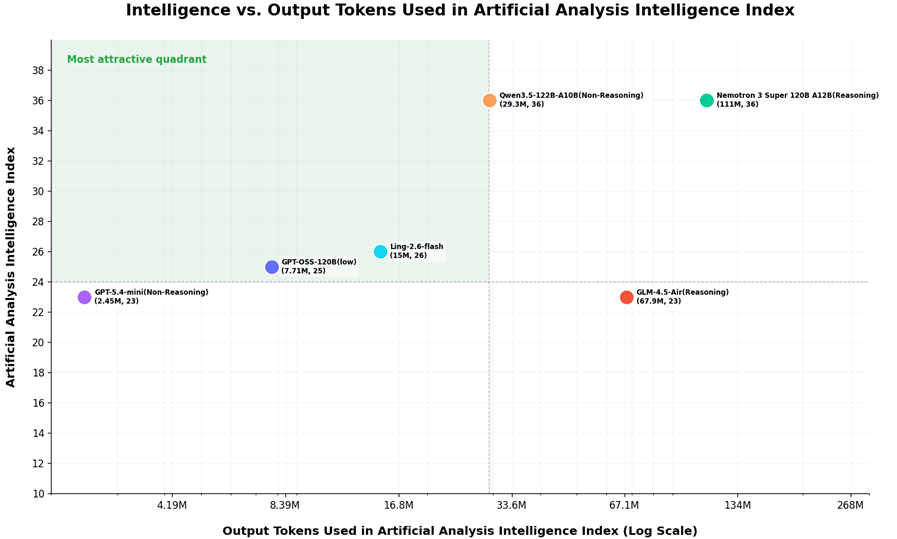
Según datos autorizados de análisis artificial de evaluación de terceros, Ling-2.6-flash demuestra ventajas sobresalientes de eficiencia de token, logrando un índice de inteligencia de 26 puntos con 15 millones de tokens de salida, mientras mantiene un fuerte nivel de inteligencia y controla el consumo de salida en una posición relativamente baja.
Se entiende que Ling-2.6-flash sigue el diseño de arquitectura lineal híbrida de Ling 2.5. Esta arquitectura MoE muy escasa tiene ventajas obvias en el rendimiento del hardware.
Bajo la condición de 4 tarjetas H20, la velocidad de inferencia puede alcanzar hasta 340 tokens/s y el rendimiento de prellenado alcanza 2,2 veces el de Nemotron-3-Super.
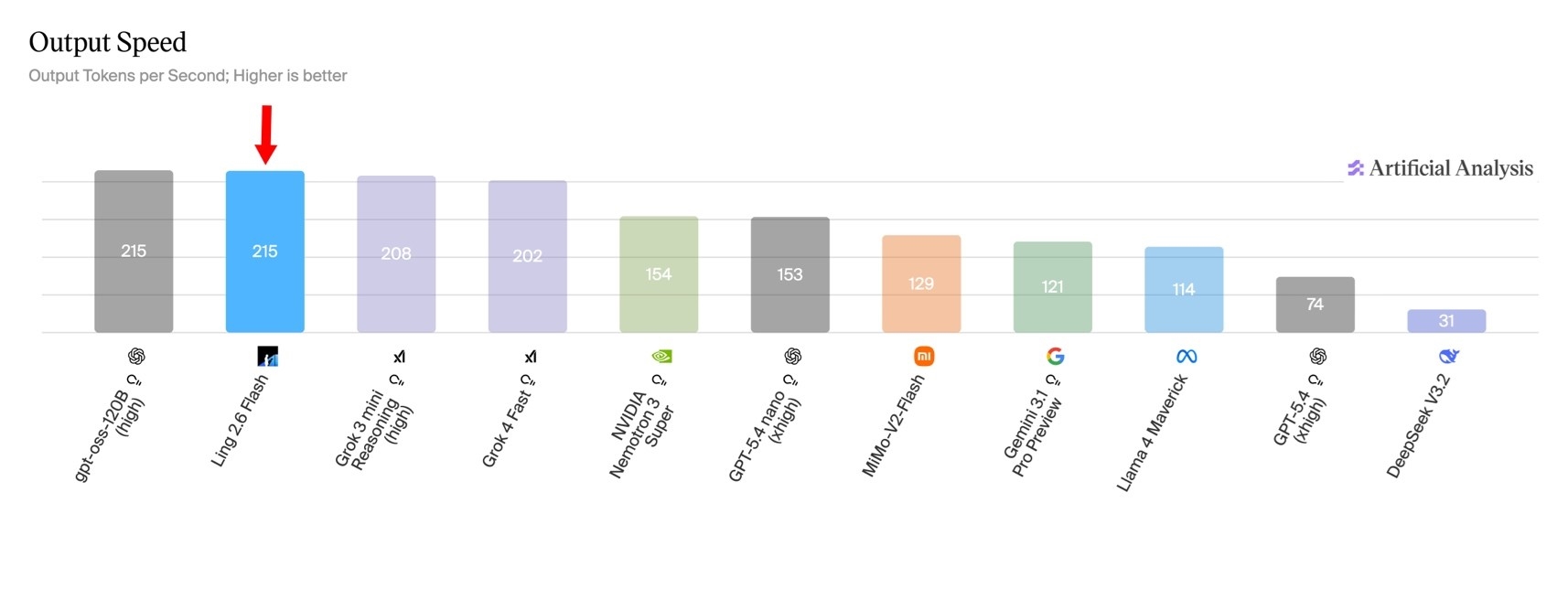
En la evaluación de Velocidad de salida, Ling-2.6-flash ocupó el primer lugar entre los modelos del mismo nivel de parámetro con una velocidad de salida estable de 215 tokens/s.
Desde la perspectiva del consumo de tokens, la relación de E/S de Ling-2.6-flash ha mejorado significativamente.
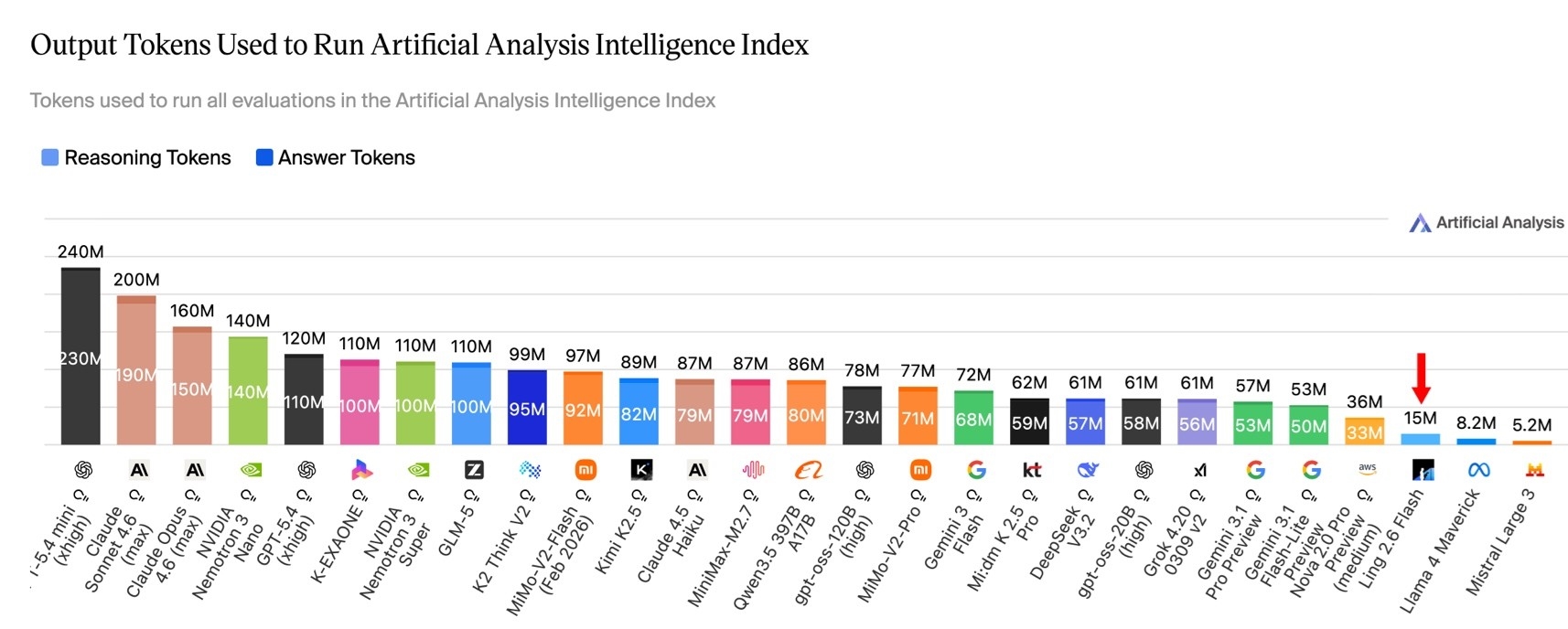
En la evaluación completa del Análisis Artificial, el consumo total de Ling-2.6-flash fue de 15 millones de tokens, mientras que modelos como Nemotron-3-Super alcanzaron o superaron los 110 millones de tokens. Esto significa que Ling-2.6-flash solo utiliza aproximadamente 1/10 del consumo de tokens para completar tareas de evaluación similares.
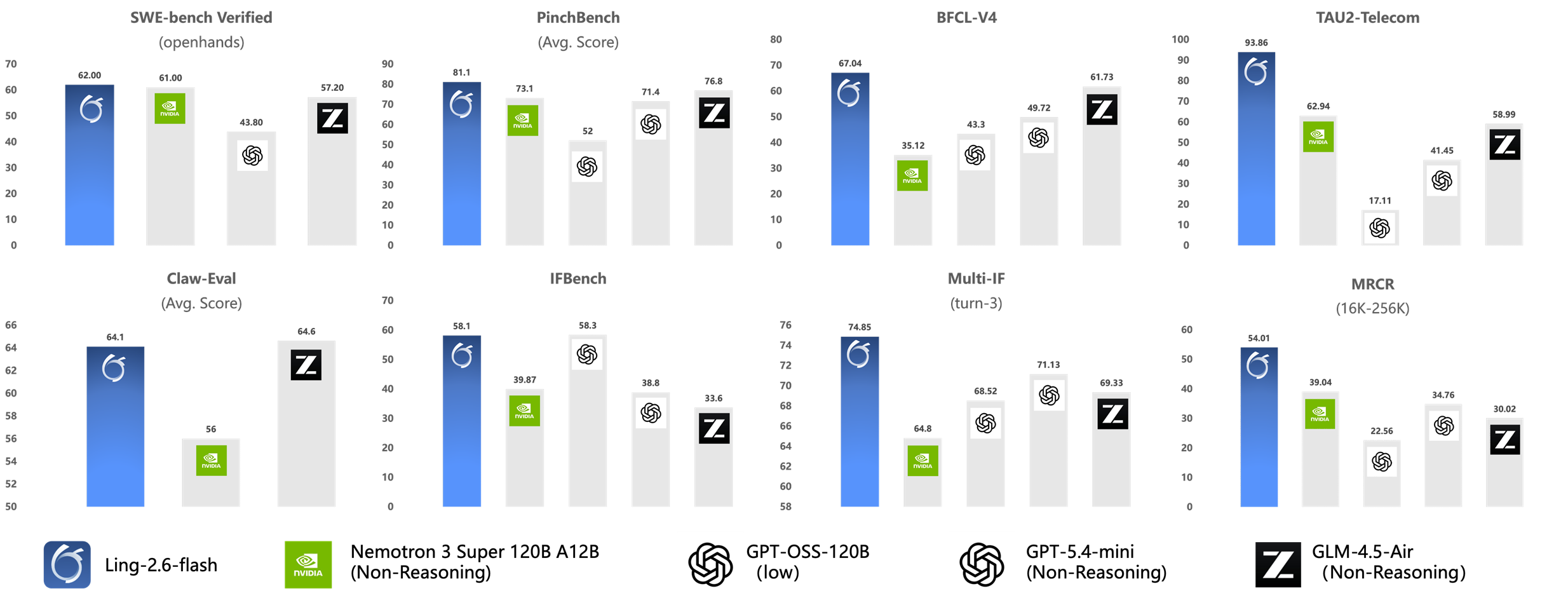
Ling-2.6-flash ha realizado mejoras específicas para los escenarios de Agentes. Aún mantiene sólidas capacidades de ejecución de tareas mientras controla el consumo de tokens. El modelo ha alcanzado el nivel SOTA del mismo tamaño en pruebas comparativas relacionadas con agentes como BFCL-V4, TAU2-bench, SWE-bench Verified, Claw-Eval y PinchBench.
Al mismo tiempo, Ling-2.6-flash mantiene niveles excelentes en dimensiones como conocimiento general, razonamiento matemático, seguimiento de instrucciones y análisis de textos largos.
En términos de precios de API, Ling-2.6-flash tiene un precio de 0,1 dólares estadounidenses por millón de tokens para entrada y 0,3 dólares estadounidenses para salida.Actualmente, la API de Ling-2.6-flash se ha abierto oficialmente a los usuarios y se ofrece una prueba gratuita por tiempo limitado de una semana.
Los usuarios pueden obtener los servicios correspondientes a través de OpenRouter y Bailing modelo grande tbox. Se entiende que el modelo lanzará posteriormente una versión comercial, LingDT, a través de Ant Digital para servir a desarrolladores globales y pequeñas y medianas empresas.