Google lanzó hoy oficialmente Gemini 3.1 Flash-Lite, afirmando que es el modelo más rápido y rentable de la serie Gemini 3. También dijo que 3.1 Flash-Lite está diseñado para cargas de trabajo de alto rendimiento y gran escala de desarrolladores y demuestra una calidad extremadamente alta en su rango de precios y nivel de modelo.
A partir de hoy, 3.1 Flash-Lite estará disponible como vista previa para los desarrolladores a través de la interfaz Gemini en Google AI Studio y estará disponible para los usuarios empresariales a través de Vertex AI.
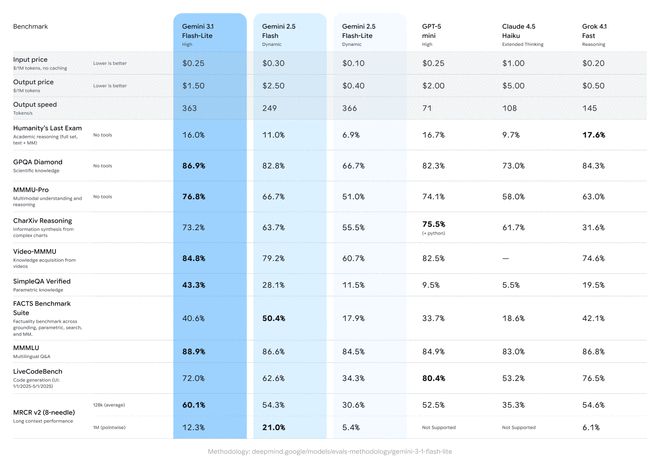
3.1 Flash-Lite cuesta 0,25 dólares estadounidenses por millón de tokens de entrada (tokens de entrada) y 1,50 dólares estadounidenses por millón de tokens de salida (tokens de salida). Según la prueba comparativa de Artificial Analysis, 3.1 Flash-Lite funciona mejor que 2.5 Flash manteniendo la misma o mayor calidad. Su velocidad de respuesta de la primera palabra (tiempo hasta la primera respuesta) ha aumentado 2,5 veces y la velocidad de salida también ha aumentado un 45%. Google dice que esta característica de baja latencia es imprescindible para los flujos de trabajo de alta frecuencia, lo que la convierte en un modelo ideal para que los desarrolladores creen experiencias responsivas en tiempo real.
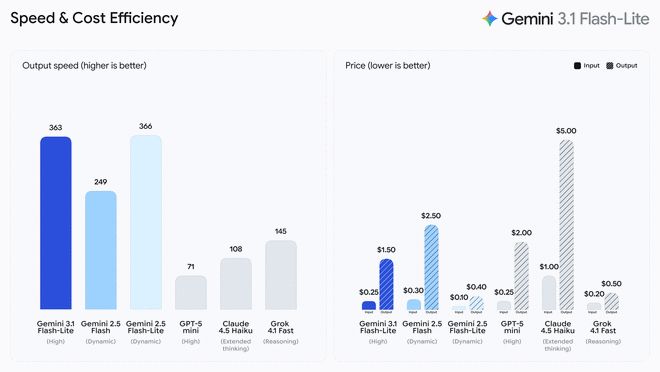
3.1 Flash-Lite obtuvo 1432 puntos en la clasificación de Arena.ai. En diversas pruebas de referencia de razonamiento y comprensión multimodal, su desempeño supera a otros modelos del mismo nivel. Por ejemplo, logró una puntuación del 86,9% en la prueba GPQA Diamond y del 76,8% en la prueba MMMU Pro. Este rendimiento supera incluso a generaciones anteriores de modelos más grandes, como el 2.5 Flash.
Además del rendimiento nativo, Gemini 3.1 Flash-Lite también viene de serie con la funcionalidad "Thinking Level" en AI Studio y Vertex AI. Esto brinda a los desarrolladores la flexibilidad de controlar qué tan profundamente "piensan" sus modelos para tareas específicas, lo cual es fundamental para administrar cargas de trabajo de alta frecuencia. 3.1 Flash-Lite es capaz de manejar tareas a gran escala, como traducción de gran volumen y moderación de contenido, que son económicas. Al mismo tiempo, también es capaz de realizar tareas complejas que requieren un razonamiento profundo, como generar interfaces de usuario y paneles, crear entornos de simulación y seguir instrucciones complejas.
Google dijo que los desarrolladores de acceso temprano de AI Studio y Vertex AI, así como empresas como Latitude, Cartwheel y Whering, ya están utilizando 3.1 Flash-Lite para resolver problemas complejos a escala. Los primeros evaluadores destacaron la eficiencia y las capacidades de inferencia de 3.1 Flash-Lite. Dijeron que el modelo puede manejar entradas complejas con la precisión de modelos a gran escala, y puede seguir estrictamente instrucciones y mantener un alto grado de coherencia.