Finalmente se lanzó la versión preliminar de DeepSeek-V4. Hoy, DeepSeek anunció oficialmente que se han lanzado y son de código abierto dos modelos, deepseek-v4-pro y deepseek-v4-flash, con un contexto ultralargo de un millón de palabras. De ahora en adelante, puede iniciar sesión en el sitio web oficial o en la aplicación oficial para hablar con el último DeepSeek-V4 y explorar la nueva experiencia de 1 millón (millón) de memoria de contexto ultralarga. El servicio API se ha actualizado simultáneamente.

Texto | Columna "ERROR" Zhou Wenmeng

Según la evaluación comparativa oficial, el rendimiento de DeepSeek V4 es comparable al de los principales modelos internacionales de código cerrado en términos de longitud del contexto, conocimiento, razonamiento y capacidades del agente, y ha alcanzado el nivel de primera clase de los modelos internacionales de código abierto. Una comparación en la columna "ERROR" encontró que en términos de precios de llamadas API, la versión V4 de DeepSeek, que por sí sola impulsó recortes de precios en la industria nacional de modelos grandes el año pasado, una vez más estableció el "precio más bajo" en la industria.
"Aunque el precio call por millón de tokens de los modelos nacionales no ha bajado mucho, ¡la larga duración del contexto y el buen rendimiento le dan una ventaja muy competitiva!" Algunas personas de la industria se lamentaron al comunicarse con la columna "ERROR": "¡Ese carnicero de gran precio modelo ha vuelto!"
El rendimiento es comparable al de los mejores modelos de código cerrado y las capacidades de conocimiento y razonamiento son líderes.
Según la introducción oficial de DeepSeek, la serie V4 incluye dos versiones del modelo: DeepSeek-V4-Pro con 1,6T de parámetros totales, 49B de parámetros de activación y 33T de datos de preentrenamiento; DeepSeek-V4-Flash con 284B de parámetros totales, 13B de parámetros de activación y 32T de datos de preentrenamiento; Ambos admiten de forma nativa 1 millón de contextos simbólicos.
Según los datos de las pruebas comparativas divulgadas por DeepSeek, en las pruebas de conocimiento y razonamiento, DeepSeek-V4-Pro-Max logró el mejor rendimiento en las pruebas Apex Shortlist y Codeforces, superando modelos internacionales como Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight, etc., mostrando sólidas capacidades lógicas y algorítmicas; en SimpleQA En la prueba verificada, está ligeramente por detrás de Gemini-3.1-Pro-High pero por delante de Claude y GPT.
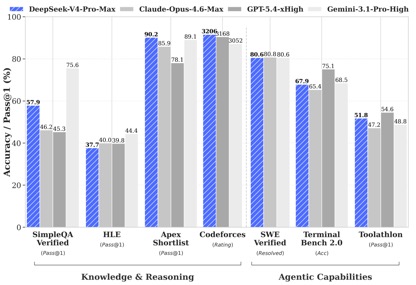
En la evaluación de capacidad de Agentic, los tres modelos V4, Opus-4.6 y Gemin-3.1-pro quedaron empatados en la tarea SWE Verified, y DeepSeek alcanzó un nivel segundo después de GPT-5.4-xHigh en la tarea Toolathlon, y logró un nivel mejor que Opus-4.6 en Terminal Bench 2.0, lo que refleja sus ventajas en la ejecución de comandos complejos y escenarios de invocación de herramientas.
En la actualidad, DeepSeek-V4 se ha convertido en el modelo de codificación agente utilizado por los empleados internos de la empresa. Según los comentarios de la evaluación, la experiencia de uso es mejor que la de Sonnet 4.5 y la calidad de entrega es cercana al modo sin pensamiento de Opus 4.6.
En la evaluación de matemáticas, STEM y códigos competitivos, DeepSeek-V4-Pro superó a la mayoría de los modelos de código abierto que han sido evaluados públicamente y logró resultados comparables a los mejores modelos de código cerrado del mundo.
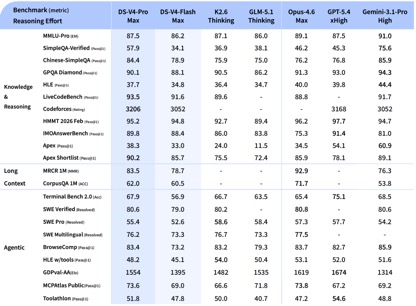
En conjunto, en términos de capacidades de razonamiento y procesamiento de conocimientos, DeepSeek-v4 ha logrado una ventaja general sobre los modelos nacionales de código abierto y es comparable a las capacidades de evaluación internacional. Sin embargo, en términos de capacidades Agentic, aunque el último DeepSeek-v4 ha logrado buenas mejoras, la brecha entre las capacidades de primer nivel nacionales e internacionales no se ha ampliado, y cada uno está por delante.
"Configuración estándar: 1 millón de contextos,The Price Butcher está "de regreso"
En comparación con las ventajas de rendimiento reflejadas en varias pruebas comparativas, la característica más importante de esta versión V4 es el gran avance en las capacidades de texto largo y la reducción adicional de los precios de las llamadas API.
Gracias al nuevo mecanismo de atención iniciado por DeepSeek-V4, V4 logra capacidades de contexto largo líderes en el mundo al comprimir la dimensión del token y combinarla con atención dispersa DSA (DeepSeek Sparse Attention), y reduce significativamente los requisitos de memoria informática y gráfica en comparación con los métodos tradicionales, lo que convierte a 1M (un millón) de contexto en el estándar para todos los servicios oficiales de DeepSeek.
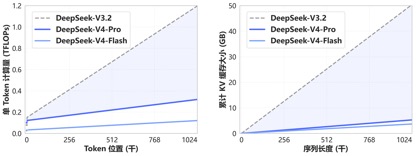
Hace un año, 1 millón de contextos era la carta de triunfo exclusiva de Géminis. Incluso en la mayoría de los principales modelos nacionales de código abierto lanzados recientemente, la longitud del contexto del modelo estaba principalmente en el rango de 128K-200K. Sin embargo, DeepSeek transformó directamente el millón de contextos de una "función de código cerrado de alto nivel" a un estándar de código abierto.
En términos de precios de API, en comparación con el precio unitario de entrada actual de GLM-5.1 de 1,3 yuanes-2 yuanes/millón de tokens (impacto de caché) y Kimi-K2.6 de 1,1 yuanes/millón de tokens (impacto de caché), los precios unitarios de entrada de DeepSeek-v4-pro y las versiones flash son de 1 yuan/millón de tokens y 0,2 yuanes/millón de tokens respectivamente. Aunque la caída de precios no es grande, es la más baja y la duración del contexto se ha ampliado varias veces.
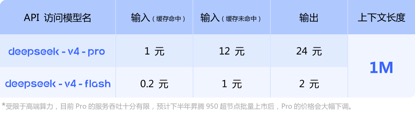
(Precio de llamada API del modelo de la serie DeepSeek-v4)
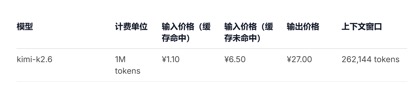
(Precio de llamada API del modelo Kimi-k2.6)
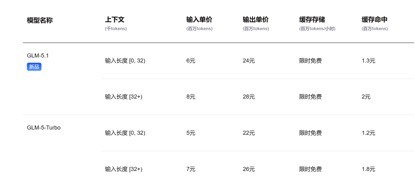
(Precio de llamada API del modelo GLM-5.1)
"El avance en el rendimiento logrado con el lanzamiento de DeepSeek-v4 tiene menos impacto que el lanzamiento de DeepSeek-R1. El rendimiento todavía está en el primer escalón, pero el liderazgo no se ha extendido por completo". Según los expertos de la industria, "el lanzamiento del modelo V4 tiene más que ver con la mejora de las capacidades de texto largo y una mayor reducción del precio".
Esta persona se lamentó: "Después del lanzamiento de los modelos DeepSeek-V3 y R1, las ventajas de rendimiento aportadas por la innovación tecnológica subyacente han promovido directamente la reducción colectiva de precios de toda la industria nacional de modelos grandes. Aunque el precio de compra por millón de tokens de la versión V4 no ha bajado mucho en comparación con sus pares nacionales, sigue siendo competitivo. ¡El carnicero de precios de los grandes modelos ha vuelto! "
"La potencia informática de Huawei se agregará en lotes en la segunda mitad del año y el precio de Pro se reducirá significativamente".
Vale la pena señalar que al final de la información de precios de API publicada por DeepSeek-v4, el aviso oficial dice: "Limitado por la potencia informática de alta gama, el rendimiento del servicio de Pro es actualmente muy limitado. Se espera que el precio de Pro se reduzca significativamente después del lanzamiento del supernodo Ascend 950 en lotes en la segunda mitad del año".

Esto significa que los modelos de la serie v4 lanzados esta vez se han adaptado al supernodo Huawei Ascend 950. Mientras se lance el Ascend 950, los usuarios podrán utilizar DeepSeek-v4 basado en una potencia informática nacional comparable a los principales modelos internacionales de código cerrado.
En la documentación técnica oficial de código abierto, DeepSeek también mencionó esto, afirmando que v4 ha verificado la solución EP (Expert Parallelism) detallada en las plataformas NVIDIA GPU y HUAWEI Ascend NPU. En comparación con la potente línea de base sin fusión, puede lograr una aceleración de 1,50 a 1,73 veces en tareas de razonamiento general y una aceleración de 1,96 veces en escenarios sensibles al retraso (como la deducción de RL y los servicios de proxy de alta velocidad).

Después del lanzamiento de V4, Huawei Ascend también anunció que "toda la gama de productos de supernodo es compatible con los modelos de la serie DeepSeek V4". Se informa que Ascend 950 reduce el cálculo de atención y la sobrecarga de acceso a la memoria al integrar el kernel y la tecnología paralela de flujo múltiple, mejorar en gran medida el rendimiento de inferencia y combinar múltiples algoritmos de cuantificación para lograr un alto rendimiento y una implementación de inferencia del modelo DeepSeek V4 de baja latencia.
A principios de este mes, el fundador de Nvidia, Huang Jenxun, dijo en una entrevista exclusiva con Dwarkesh Patel: "Si DeepSeek se lanza primero en la plataforma Huawei, será desastroso para nuestro país (Estados Unidos)". En opinión de Huang, aunque DeepSeek es un modelo de código abierto y también se puede utilizar en productos Nvidia, si DeepSeek se optimiza específicamente para la potencia informática de Huawei, Nvidia estará en desventaja debido a limitaciones como restricciones en la compra de potencia informática de alta gama.
Ahora parece que, aunque DeepSeek también ha verificado la solución EP para la potencia informática de Nvidia, lo que preocupaba a Huang Renxun todavía ha sucedido. En opinión de los expertos de la industria, "V4 es un producto impulsado por el juego de la potencia informática. Durante el próximo año, los grandes modelos nacionales que funcionan con tarjetas nacionales madurarán gradualmente".
Las capacidades multimodales aún están por surgir
Desafortunadamente, aunque se lanzó DeepSeek V4, esta versión sigue siendo un modelo de texto puro sin muchas capacidades multimodales, como imágenes y videos de Vincent. Esto también permite a los usuarios comunes experimentar y evaluar rápidamente un modelo, lo que añade mucha dificultad.

Después de todo, a medida que las capacidades de los grandes modelos de lenguaje continúan mejorando y la tasa de alucinaciones disminuye gradualmente, es difícil que las preguntas y respuestas convencionales y de conocimiento único reflejen objetivamente las capacidades integrales de un modelo. Para la mayoría de los usuarios, si quieren experimentar intuitivamente las capacidades del modelo V4, deben descargarlo y usarlo personalmente por un tiempo.
Al mismo tiempo que el lanzamiento de la serie de modelos V4, DeepSeek también reveló recientemente que planea recaudar 50 mil millones de yuanes. Personas cercanas a DeepSeek revelaron que la valoración de prefinanciación de DeepSeek es de 300 mil millones de yuanes, aproximadamente 44 mil millones de dólares. Actualmente, Tencent Holdings y Alibaba Group están negociando para invertir en DeepSeek. Sin embargo, DeepSeek no ha respondido directamente a las consultas de los medios sobre asuntos relacionados con la financiación.
Quizás, para el fundador de DeepSeek, Liang Wenfeng, también sea una decisión inteligente utilizar el lanzamiento de V4 para recaudar financiamiento oportuno para fortalecer su fuerza cuando el crecimiento de la "inteligencia" de los grandes modelos globales se está desacelerando, la competencia por los talentos de la industria se está intensificando y las tendencias multimodales y agentes de la industria se destacan cada vez más.