Aunque NVIDIA actualmente no tiene rival en el campo del entrenamiento de IA, ante la creciente demanda de razonamiento en tiempo real, está planeando un "arma secreta" que puede cambiar el panorama de la industria. Según AGF,NVIDIA planea integrar la LPU (Unidad de procesamiento del lenguaje) de Groq en la GPU de arquitectura Feynman lanzada en 2028 para mejorar significativamente el rendimiento de la inferencia de IA.
La arquitectura Feynman sucederá a la arquitectura Rubin y utilizará el proceso A16 (1,6 nm) más avanzado de TSMC. Para superar las limitaciones físicas de los semiconductores, NVIDIA planea utilizar la tecnología de enlace híbrido SoIC de TSMC para apilar unidades LPU diseñadas específicamente para la aceleración de inferencia directamente encima de la GPU.
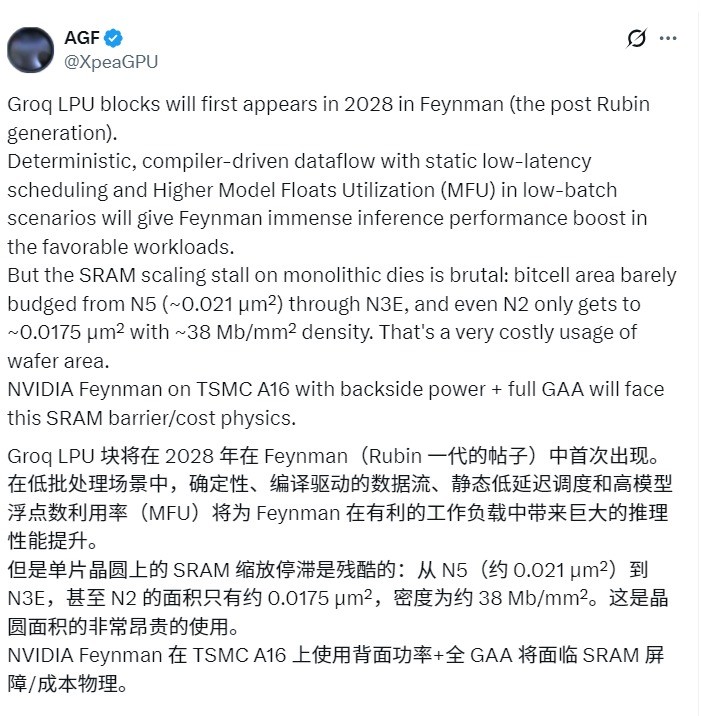
Este diseño es similar a la tecnología 3D V-Cache de AMD, pero NVIDIA no apila cachés comunes, sino unidades LPU diseñadas específicamente para la aceleración de inferencia.
La lógica central del diseño es resolver el dilema de escala de SRAM. En el proceso extremo de 1,6 nm, integrar una gran cantidad de SRAM directamente en el chip principal es extremadamente costoso y ocupa espacio.
A través de la tecnología de apilamiento, NVIDIA puede mantener el núcleo informático en el chip principal y apilar la SRAM que requiere un área grande en otra capa de chips.
Una característica importante del proceso A16 de TSMC es que admite tecnología de suministro de energía trasera. Esta tecnología puede liberar espacio en la parte frontal del chip para conexiones de señales verticales, garantizando que las LPU apiladas puedan realizar intercambios de datos de alta velocidad con un consumo de energía extremadamente bajo.

En combinación con la lógica de ejecución "determinista" de la LPU, las futuras GPU de NVIDIA lograrán un salto cualitativo en velocidad al procesar respuestas instantáneas de IA (como diálogos de voz, traducción en tiempo real).
Sin embargo, también existen dos desafíos potenciales, a saber, problemas de disipación de calor y problemas de compatibilidad CUDA.Al agregar una capa de chips a una GPU con una densidad informática extremadamente alta, cómo evitar el "accidente térmico" es el problema número uno para el equipo de ingeniería.
Al mismo tiempo, LPU enfatiza el orden de ejecución "determinista" y requiere una configuración de memoria precisa, mientras que el ecosistema CUDA está diseñado en base a la abstracción de hardware. Para lograr una sinergia perfecta entre ambos, se requiere una optimización del software de alto nivel.